之前在调研中文分词和词性标注相关工具的时候就发现了百度的深度学习中文词法分析工具:baidu/lac(https://github.com/baidu/lac),但是通过这个项目github上的文档描述以及实际动手尝试源码编译安装发现非常繁琐,缺乏通常中文分词工具的易用性,所以第一次接触完百度lac之后就放弃了:
LAC是一个联合的词法分析模型,整体性地完成中文分词、词性标注、专名识别任务。LAC既可以认为是Lexical Analysis of Chinese的首字母缩写,也可以认为是LAC Analyzes Chinese的递归缩写。
LAC基于一个堆叠的双向GRU结构,在长文本上准确复刻了百度AI开放平台上的词法分析算法。效果方面,分词、词性、专名识别的整体准确率95.5%;单独评估专名识别任务,F值87.1%(准确90.3,召回85.4%),总体略优于开放平台版本。在效果优化的基础上,LAC的模型简洁高效,内存开销不到100M,而速度则比百度AI开放平台提高了57%。
本项目依赖Paddle v0.14.0版本。如果您的Paddle安装版本低于此要求,请按照安装文档中的说明更新Paddle安装版本。如果您使用的Paddle是v1.1以后的版本,请使用该项目的分支for_paddle_v1.1。注意,LAC模块中的conf目录下的很多文件是采用git-lfs存储,使用git clone时,需要先安装git-lfs。
为了达到和机器运行环境的最佳匹配,我们建议基于源码编译安装Paddle,后文也将展开讨论一些编译安装的细节。当然,如果您发现符合机器环境的预编译版本在官网发布,也可以尝试直接选用。
最近发现百度将自己的一些自然语言处理工具整合在PaddleNLP下,文档写得相对清楚多了:
PaddleNLP是百度开源的工业级NLP工具与预训练模型集,能够适应全面丰富的NLP任务,方便开发者灵活插拔尝试多种网络结构,并且让应用最快速达到工业级效果。
PaddleNLP完全基于PaddlePaddle Fluid开发,并提供依托于百度百亿级大数据的预训练模型,能够极大地方便NLP研究者和工程师快速应用。使用者可以用PaddleNLP快速实现文本分类、文本匹配、序列标注、阅读理解、智能对话等NLP任务的组网、建模和部署,而且可以直接使用百度开源工业级预训练模型进行快速应用。用户在极大地减少研究和开发成本的同时,也可以获得更好的基于工业实践的应用效果。
这次直接通过PaddleNLP试用LAC词法分析工具,其他NLP工具感兴趣的同学可以测试,可以直接follow文档操作,比上次便捷很多,文档在这里:百度词法分析
Lexical Analysis of Chinese,简称 LAC,是一个联合的词法分析模型,能整体性地完成中文分词、词性标注、专名识别任务。我们在自建的数据集上对分词、词性标注、专名识别进行整体的评估效果,具体数值见下表;此外,我们在百度开放的ERNIE模型上 finetune,并对比基线模型、BERT finetuned 和 ERNIE finetuned 的效果,可以看出会有显著的提升。可通过AI开放平台-词法分析线上体验百度的词法分析服务。
我是在virvutuenv下通过pip 安装 百度飞桨(PaddlePaddle),有多个版本选择,可在PaddlePaddle主页这里进行选择:安装指南
以下在Ubuntu16.04, Python3.x, CPU环境下测试和部署:
首先安装PaddlePaddel,目前是1.4.1版本:
pip install paddlepaddle
克隆工具集代码库到本地
git clone https://github.com/PaddlePaddle/models.git cd models/PaddleNLP/lexical_analysis
下载数据集文件,解压后会生成 ./data/ 文件夹
wget --no-check-certificate https://baidu-nlp.bj.bcebos.com/lexical_analysis-dataset-1.0.0.tar.gz tar xvf lexical_analysis-dataset-1.0.0.tar.gz
下载模型文件,这里没有使用PaddleHub,wget直接下载:
# download baseline model wget --no-check-certificate https://baidu-nlp.bj.bcebos.com/lexical_analysis-1.0.0.tar.gz tar xvf lexical_analysis-1.0.0.tar.gz # download ERNIE finetuned model wget --no-check-certificate https://baidu-nlp.bj.bcebos.com/lexical_analysis_finetuned-1.0.0.tar.gz tar xvf lexical_analysis_finetuned-1.0.0.tar.gz
注:下载 ERNIE 开放的模型请参考ERNIE,下载后可放在 ./pretrained/ 目录下。
然后就可以直接使用里面的脚本进行训练、评估和预测了,以下来自于官方文档:
模型评估
基于自建的数据集训练了一个词法分析的模型,可以直接用这个模型对测试集 ./data/test.tsv 进行验证
# baseline model sh run.sh eval # ERNIE finetuned model sh run_ernie.sh eval
模型训练
基于示例的数据集,可以运行下面的命令,在训练集 ./data/train.tsv 上进行训练
# baseline model sh run.sh train # ERNIE finetuned model sh run_ernie.sh train
模型预测
加载已有的模型,对未知的数据进行预测
# baseline model sh run.sh infer # ERNIE finetuned model sh run_ernie.sh infer
调用脚本跑没有问题,GPU也比CPU快很多,但是都是需要基于特定数据格式的:
训练使用的数据可以由用户根据实际的应用场景,自己组织数据。除了第一行是 text_a\tlabel 固定的开头,后面的每行数据都是由两列组成,以制表符分隔,第一列是 utf-8 编码的中文文本,以 \002 分割,第二列是对应每个字的标注,以 \002分隔。我们采用 IOB2 标注体系,即以 X-B 作为类型为 X 的词的开始,以 X-I 作为类型为 X 的词的持续,以 O 表示不关注的字(实际上,在词性、专名联合标注中,不存在 O )。示例如下:
除\002了\002他\002续\002任\002十\002二\002届\002政\002协\002委\002员\002,\002马\002化\002腾\002,\002雷\002军\002,\002李\002彦\002宏\002也\002被\002推\002选\002为\002新\002一\002届\002全\002国\002人\002大\002代\002表\002或\002全\002国\002政\002协\002委\002员 p-B\002p-I\002r-B\002v-B\002v-I\002m-B\002m-I\002m-I\002ORG-B\002ORG-I\002n-B\002n-I\002w-B\002PER-B\002PER-I\002PER-I\002w-B\002PER-B\002PER-I\002w-B\002PER-B\002PER-I\002PER-I\002d-B\002p-B\002v-B\002v-I\002v-B\002a-B\002m-B\002m-I\002ORG-B\002ORG-I\002ORG-I\002ORG-I\002n-B\002n-I\002c-B\002n-B\002n-I\002ORG-B\002ORG-I\002n-B\002n-I
我比较关注inference,不过测试其他文本都需要做一些预处理和后处理,可能我更需要的是一个全流程的脚本,给定一段文本作为输出,然后得到中文分词、词性标注、命名实体识别的结果,不过在这个目录下貌似没有找到这样的脚本或者case。
这个时候轮到PaddleHub登场了(https://github.com/PaddlePaddle/PaddleHub)
PaddleHub是基于PaddlePaddle开发的预训练模型管理工具,可以借助预训练模型更便捷地开展迁移学习工作。
特性
通过PaddleHub,您可以:通过命令行,无需编写代码,一键使用预训练模型进行预测;
通过hub download命令,快速地获取PaddlePaddle生态下的所有预训练模型;
借助PaddleHub Finetune API,使用少量代码完成迁移学习;
更多Demo可参考 ERNIE文本分类 图像分类迁移
完整教程可参考 文本分类迁移教程 图像分类迁移教程
确实非常方便,样例中已经给了快速安装方法和几个Demo的使用方法:
安装
环境依赖Python==2.7 or Python>=3.5
PaddlePaddle>=1.4.0
pip安装方式如下:$ pip install paddlehub
快速体验
安装成功后,执行下面的命令,可以快速体验PaddleHub无需代码、一键预测的命令行功能:# 使用百度LAC词法分析工具进行分词
$ hub run lac --input_text "今天是个好日子"# 使用百度Senta情感分析模型对句子进行预测
$ hub run senta_bilstm --input_text "今天是个好日子"# 使用SSD检测模型对图片进行目标检测,检测结果如下图所示
$ wget --no-check-certificate https://paddlehub.bj.bcebos.com/resources/test_img_bird.jpg
$ hub run ssd_mobilenet_v1_pascal --input_path test_img_bird.jpg
不过我想在Python中使用百度Lac,所以在 PaddleHub/demo/lac 下找到了python demo脚本,模仿着测试了一下:
Python 3.5.2 (default, Nov 12 2018, 13:43:14)
Type 'copyright', 'credits' or 'license' for more information
IPython 7.5.0 -- An enhanced Interactive Python. Type '?' for help.
In [1]: import paddlehub as hub
In [2]: lac = hub.Module(name='lac')
2019-06-26 22:23:47,446-INFO: Installing lac module
2019-06-26 22:23:47,446-INFO: Module lac already installed in /home/textminer/.paddlehub/modules/lac
In [3]: test_text =["我爱自然语言处理", "南京市长江大桥", "无线电法国别研究"]
In [4]: inputs = {"text": test_text}
In [5]: results = lac.lexical_analysis(data=inputs)
2019-06-26 22:25:18,699-INFO: 20 pretrained paramaters loaded by PaddleHub
In [6]: for result in results:
...: print(result['word'])
...: print(result['tag'])
...:
['我', '爱', '自然语言处理']
['r', 'v', 'nz']
['南京市', '长江大桥']
['LOC', 'LOC']
['无线电', '法国', '别', '研究']
['n', 'LOC', 'd', 'v']
虽然最后一个中文分词的超难Case没有搞定(这方面可以参考:中文分词八级测试),但是发现百度LAC在命名实体识别貌似比较强悍,这可以从百度LAC的词性标注集上看出端倪:
词性和专名类别标签集合如下表,其中词性标签24个(小写字母),专名类别标签4个(大写字母)。这里需要说明的是,人名、地名、机名和时间四个类别,在上表中存在两套标签(PER / LOC / ORG / TIME 和 nr / ns / nt / t),被标注为第二套标签的词,是模型判断为低置信度的人名、地名、机构名和时间词。开发者可以基于这两套标签,在四个类别的准确、召回之间做出自己的权衡。
Image may be NSFW.
Clik here to view.
最后,我已经把百度LAC加入到AINLP公众号的对话接口中,感兴趣的同学可以关注AINLP公众号,直接测试:
Image may be NSFW.
Clik here to view.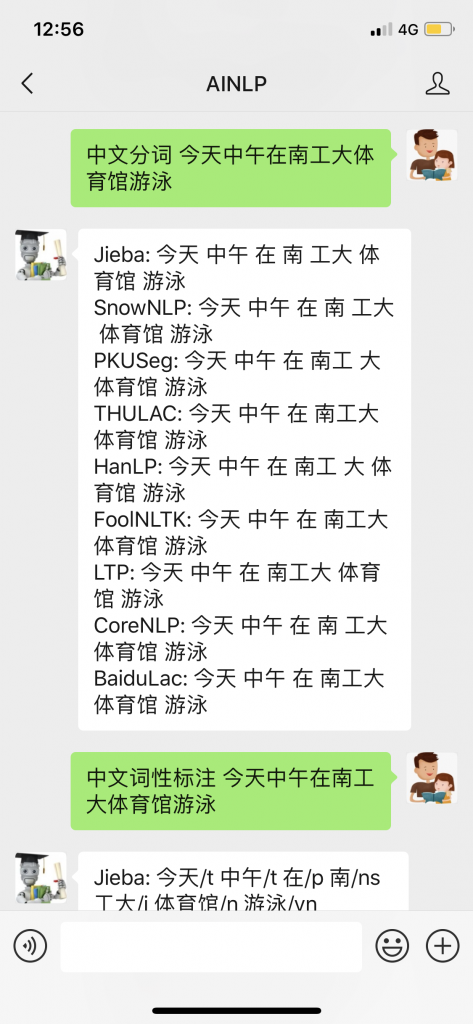
Image may be NSFW.
Clik here to view.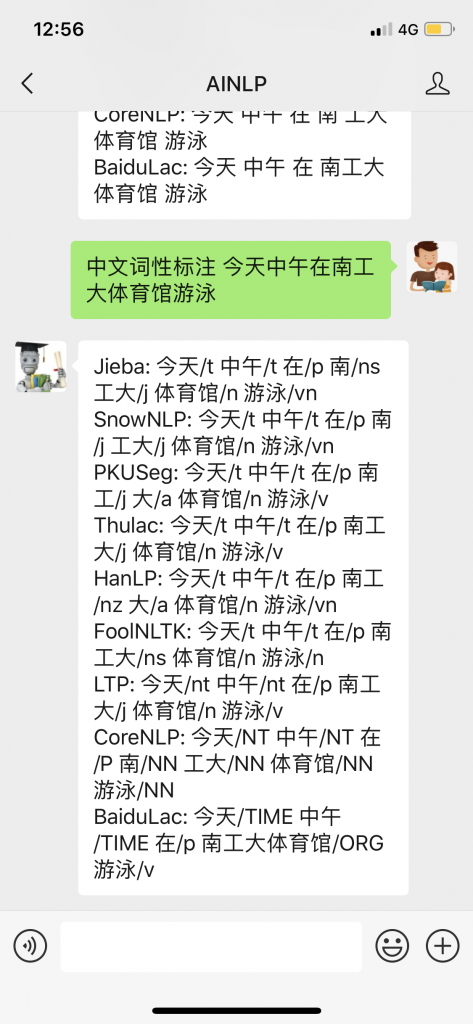
注:原创文章,转载请注明出处及保留链接“我爱自然语言处理”:http://www.52nlp.cn