本文整理自7月7日世界人工智能大会“AI生成与垂直大语言模型的无限魅力”论坛上中国工程院院士、复旦大学金融科技研究院院长柴洪峰《大模型赋能金融科技思考与展望》的主题分享,从金融垂直模型构建、金融知识图谱与大模型融合以及金融大模型的监管三个方面进行介绍。
随着金融科技的蓬勃发展,金融行业正经历着一场革命性的变革。金融垂直领域模型构建与金融数据的结合成为推动金融科技创新和发展的重要动力。通过整合跨学科研究和系统方法,能够探索金融系统的整体性和复杂性,超越单点技术突破,从而推动金融科技的突破性进展。大数据、人工智能和机器学习等技术的发展,使人们能更快速、高效地获取、分析、存储、共享和整合各种异构数据。

然而,金融垂直领域的大模型应用仍面临一些挑战。金融数据和知识的私密性限制了共享和构建大规模数据集的能力。此外,金融数据的多模态特性增加了模型处理和建模的复杂性。为了克服这些难题,加强产学研的合作势在必行,共同构建更强大的金融垂直领域基础模型,提升大模型对多模态数据的表达能力。
一、构建金融垂直领域模型
金融数据与通用大模型的结合
金融科技的崛起正在改变金融行业的面貌,实现金融科技突破对于推动金融领域的创新和发展至关重要。而整体思维和系统认知是实现金融科技突破的首要前提,金融系统是一个开放复杂巨系统,已经很难依靠“点”上的技术突破实现整体提升。所以需要将跨学科的研究和系统方法作为解决重大关键问题的首选项。
系统认知就是要从系统要素构成、互作机理和耦合作用来探索问题的解决途径。金融与实体经济是一个生命共同体,金融领域的科学突破必须突破单要素思维,从资源利用、运作效力、系统弹性和可持续性的整体维度进行思考。
数据科学和信息技术是金融领域的战略性关键技术,数据科学和分析科技的进步为金融领域的研究和知识应用提供了重要的突破机遇。大数据、人工智能、机器学习等技术的发展提供了更快速的收集、分析、存储、共享和集成异构数据的能力和高级分析方法。数据科学和信息技术能够极大提高对复杂问题的解决能力,在动态变化条件下,自动整合数据并进行实时建模,促进形成数据驱动的智慧管控。
人机混合智能技术将成为推动金融领域进步的创新驱动技术。人机混合智能技术包括自然语言处理、机器学习、计算机视觉、语音识别和智能推荐等多个领域。这些技术的发展使得人和机器间的交互变得更加智能化,人机混合智能在金融领域的应用也越来越多,最新的大模型技术,如ChatGPT、MOSS、ChatGLM等,是和目前的金融垂直领域结合的热点。
金融数据底座的构建可以包括各类金融实时数据,各类需解析的文档数据、各类非结构化数据以及信息高度浓缩文本。通过庞大的金融垂直类数据为金融大模型提供数据支撑。

对于金融垂直领域大模型的构造需要解决的关键问题有如下三点:
- 多源、异构金融数据金融数字底座构建、金融数据安全共享使用。
- 金融数据底座与大模型的融合技术,解决通用大模型在垂直领域知识匮乏、知识关联问题,同时实现模型根据数据实时更新、不断迭代。
- 基于金融科技底座的大模型对于金融科技多领域的应用赋能,展现金融垂直领域涌现能力。
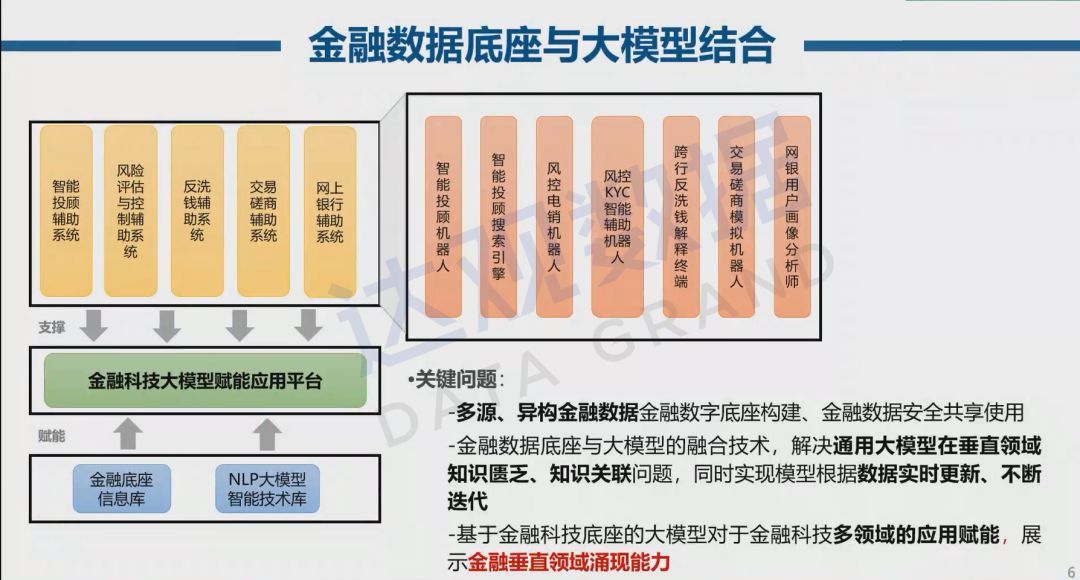
然而目前大模型在金融垂直领域仍未挖掘出涌现效应,一方面是由于金融数据及知识的私密性导致难以共享,无法构建一个庞大的数据集,对此可以增强产学研的联动性,共同构建更强的金融垂直领域基座模型。另一方面由于金融数据模态更多,难以进行统一的处理建模,而如今的大模型对此种多模态的表达能力仍有待加强。
二、关于知识图谱与大模型的融合
知识驱动与数据驱动的交互
在过去的研究中,我们构建金融知识图谱系统,其过程多为从研报、财报等各类非结构化文本信息中抽取多源异构知识,通过实体对齐、实体消歧等知识融合方法完善庞大复杂的金融知识图谱,并通过分布式图数据库存储图数据,便于后续分布式图算法的开发与应用,这些已构建的金融知识图谱在大模型时代仍有其不可替代的应用。
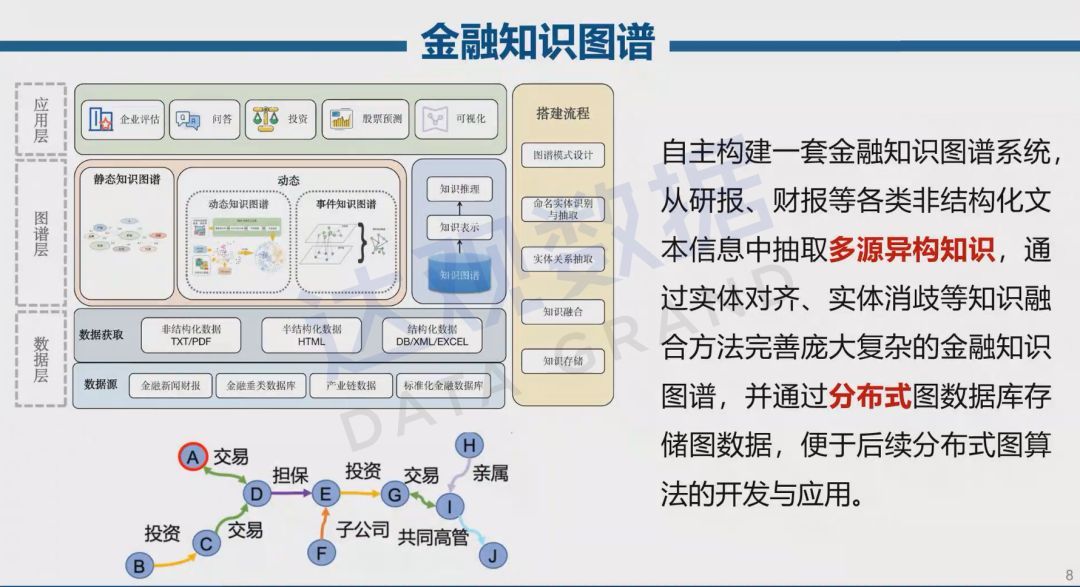
知识图谱是过去对显示知识的一种符号化表达,大模型是新兴对隐性知识的表达。在大模型时代,也不能完全摒弃已构建的海量知识图谱,知识图谱能够指导大模型对行业进行正确精准的认知,提高其理解、推理决策的能力,同时知识图谱及专家知识库解决问题的范式需要基于统计学习的大模型范式相融合,才能更好推动领域内涌现能力的出现,我们需要把以知识图谱为代表的知识驱动方法,基于利用静态以及动态的知识图谱,与以大模型为代表的数据驱动方法进行持续交互,运用多种模式,以达到知识图谱与大模型的完美结合。以人机结合方式解决现实中的复杂问题,在认知的过程中,通过人机协同挖掘一些很难由人类或计算机单独发现的新知识。

三、关于金融大模型的监管
从安全角度解决大模型的部署问题
金融数据和垂直领域大模型密切相关,存在数据安全、大模型安全可信和伦理等问题,同时金融领域也涉及敏感信息和决策,因此对于金融大模型的监管必不可少:
- 建立监管框架与标准,确保大模型在金融领域的应用符合法规与道德要求,通过政产学研的合作制定相关的政策和指南。
- 对于金融大模型的部署与使用,需要协同共治,提升透明度,保证数据质量和可解释性的机制。这可以帮助用户与监管机构理解模型的决策依据,并确保其不带有偏见或歧视性。
- 监管机构还应加强对于金融大模型的审查和风险评估,对于关键人物和系统,应建立审查和测试的机制,确保其性能和安全性。
具体来讲可分为数据安全与版权安全两个方面:
数据安全:
- 大模型的复杂性和规模增加了攻击者进行攻击的可能性。同时,大模型的训练过程涉及更多的数据和计算资源,这也无恶意攻击者提供了更多的机会来入侵和篡改数据模型。目前大模型极易通过对抗攻击、后门攻击、模型窃取等手段而遭受威胁,需要寻找有效的方法规避风险。
- 大模型在辅助金融场景知识问答的过程中,由于无法对用户身份进行识别,容易产生高等级或机密信息泄露等风险,需要对大模型训练过程中的数据安全等级做严格的界定。
版权安全:
在金融垂直领域大模型开源的情况下,被恶意窃取并进行微调的现象时有发生,可利用特定的数据进行输入,模型识别到这一特定的输入,就会给出不同于正常类的输出,通过这一行为来判断模型的归属问题。最后,柴院士表示,站在新的历史起点上,在新的历史方位和发展格局中,复旦大学金融科技研究院将针对金融科技发展的科学问题,聚焦国家重点关键性、基础性、牵引性战略需求任务,发挥产学研协同优势,攻关金融为实体经济服务的关键技术,对上海国际金融中心、科创中心建设贡献复旦力量。
作者介绍

柴洪峰
中国工程院院士、复旦大学金融科技研究院院长、教授,博士生导师