
参与任务
中文拼写检查任务是中文自然语言处理中非常具有代表性和挑战性的任务,其本质是找出文本段落中的错别字。这项任务在各种领域,如公文,新闻、财报中都有很好的落地应用价值。而其任务的困难程度也赋予了它非常大的研究空间。达观数据在CCL2022汉语学习者文本纠错评测比赛的赛道一中文拼写检查(Chinese Spelling Check)任务中取得了全国冠军,赛道二中文语法纠错(Chinese Grammatical Error Diagnosis)任务中获得了亚军。本文基于赛道一中文拼写检查任务的内容,对比赛过程中采用的一些方法进行分享,并介绍比赛采用的技术方案在达观智能校对系统中的应用和落地。赛道二中文语法纠错的获奖方案已经分享在达观数据官方公众号中。
本次中文拼写检查的任务是检测并纠正中文文本中的拼写错误(Spelling Errors)。拼写任务包括:音近,形近,音形兼近。特点是错误内容与被替换内容长度相同,这也意味着输入语句与输出语句的长度相同。
 图1 音近字错误示例
图1 音近字错误示例
在上述图1描述的案例中,输入句中的“干”是一处近音字的错误使用,应被替换为正确的“赶”,从而得到输出句子。
 图2多字错误示例
图2多字错误示例
这种任务在实际应用中会遇到一些困难。1. OOV(out of vocabulary)的问题会严重影响模型效果。首先,模型不可能纠错出没有在训练中见过的表达方式;其次,模型会由于在训练中没有见过相关实体而将他们错纠。2. 如上图2所示,当一个句子存在多处错误(糊涂两个字都错了),纠错时会受到上下文的影响,也就是受到其他错误的影响导致难以纠错成功。
纠错系统
如图3所示,纠错系统顾名思义是以一个系统流程的方式进行纠错任务。我们的系统为串联式,共有五个步骤。首先,我们对基础模 型进行预训练和微调,然后进行多轮纠错式推理,第三步是使用训练好的困惑度模型进行误召回检查,第四步则是使用实体纠错方法对于相关实体再次审核,最后使用精度很高但召回较低的Ngram语言模型进行再一次的补充。详细内容的介绍将会在该模块下逐一展开。
 图3 拼写纠错方案流程图
图3 拼写纠错方案流程图
拼音编码基础模型
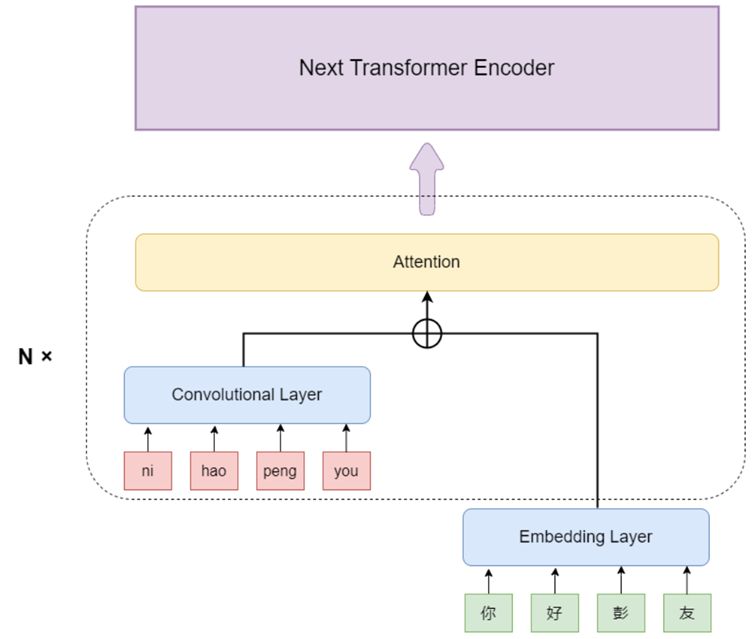
图4 拼音编码模型结构
不同于常规的BERT模型,这次工作中,我们加强了模型对属于文本拼音的识别,这样可以针对性地面对近音字问题。如图4所示,除了常规的Embedding Layer,也就是字符的编码外,我们还加入了拼音输入。我们借鉴了DCN (Wang et al., 2021)中采用的编码方法,每一个拼音组合首先会被编码成一个独一无二的整数,输入模型中。而后,将拼音经过Convolutional layer后的矩阵与文本经过Embedding Layer之后的矩阵相加,再输入到Attention中,以此强化拼音编码在模型中的权重。不同于DCN中只在Embedding阶段将拼音编码与字符编码相组合,我们借鉴了DeBERTa (He et al., 2020)中所提及的Disentangled attention方法,此过程将在每一次的Transformer encoder中进行重复。在模型训练方面,我们借鉴cbert (Liu et al., 2021)中文拼写检查模型,在大规模语料中进行训练和微调,对于无标注数据则采用混淆集自动生成数据的方法进行构造。cbert是基于混淆集构造的bert模型,由于我们需要大量未标注数据来扩大模型训练的数据量,使用混淆集来生成纠错错误对变得尤为关键。而cbert所表述的方法与我们的要求一致,所以我们采用了该方法。在除了拼音编码的部分之外,模型其余构造和base bert (Devlin et al., 2019)的结构相同。共有12个transformer层,hidden units的大小为768,attention head共有12个。而输出层则是拼接了一个输入维度为768,输出维度为单词数量的全连接层。最终再使用Softmax计算出每个备选单词的概率。
多轮纠错系统
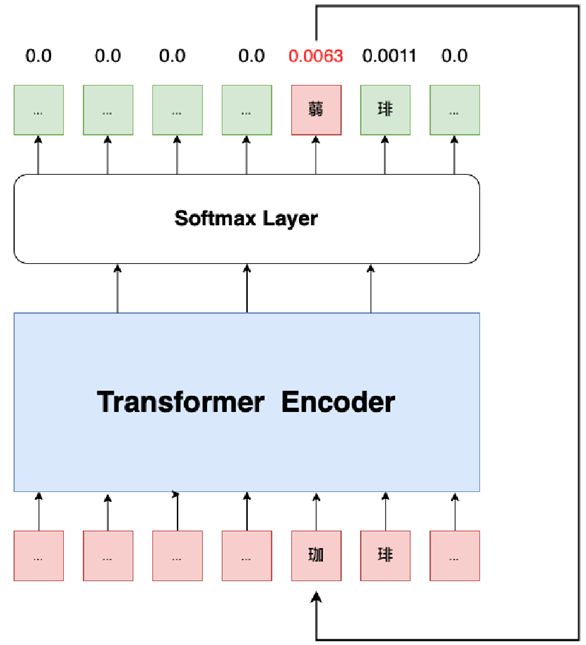
图5 多轮纠错方案模型结构
在中文拼写检查领域,解决同一句话存在多个错误的问题一直是一项重要的挑战。其原因是存在错误的上下文会对预测产生影响。在之前的工作中,CRASpell (Liu et al., 2022)通过在训练时随机在错字周围生成新的错字来模拟单句多错字的环境,但这种方法也会对数据的真实分布产生影响。一般的Transformer类纠错模型,会在每个位置返回其概率最大的字,如果存在多个错字,也将一并返回。而我们对此提出了多轮纠错的方法。如上图5所示,具体来说,如果一句话中存在多个错误,在模型预测阶段,我们每次只选取预测错误概率最高的字,将其更正后放回原句,再进行第二轮的纠错,直到不再出现新的错误的句子。
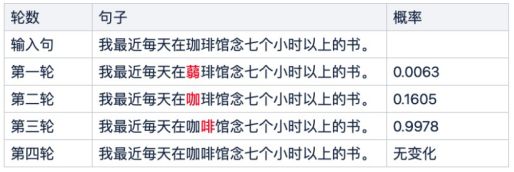
图6 多轮纠错-每一轮纠错结果示例
以上方图6为例,第一轮纠错模型将“珈”纠错成“蒻”字,在第二轮再把“草头弱”纠错成“咖”,最后由于“咖”对于上下文的补充,本来无法纠出的“琲”也被以非常高的概率成功纠错成“啡”。该方法将所有单句多错字问题转换成了单句单错字问题,使得训练与预测的任务更具有一致性,分布更加统一,并且没有丢弃任何输入信息。
困惑度减少误召回
误召回问题同样是中文拼写检查中面临的挑战。由于纠错任务本质是选取位置上概率最高的字,所以会不时出现”用正确的字替换正确的字“的情况。我们通过对比句子修改前后的困惑度来减少误召回的情况 (Bao, 2021)。
该方法主要由以下几个步骤组成:
- 针对一句话,将每个字依次[MASK]。例如:我在吃饭。将被MASK成四个sequence:[MASK]在吃饭,我[MASK]吃饭,我在[MASK]饭,我在吃[MASK]。
- 将上述四个句子经过tokenizer编码后输入进模型。
- 返回所有[MASK]字符对于原字的预测概率。一整句话也就变成:[P1, P2, ..., Pn]
- 为这组概率计算一个整体分数:
![]()
![]()
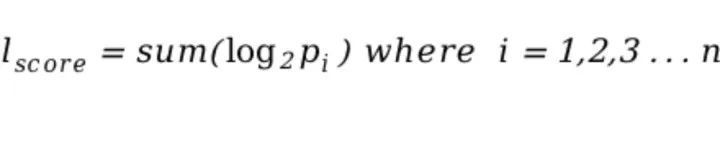

故此,socre较大的句子较socre较小的句子更为不通顺。
 图7 句子困惑度示例
图7 句子困惑度示例
上述图7中的例子显示,模型将“我知道他很忙,没有时间跟我联系。”误纠成“我知道他很忙,没有时间跟我练习。”,由于输入句本身就是通顺的句子,所以困惑度并未因此上升,这个误召回的情况也就可以被成功减少。该方法对于纠错的整体性有着针对性的提高,会减少出现句子部分纠错正确但未全部纠错正确的情况,弊端是对于字符级别的纠错性能可能带来损失。
实体纠错
当错字出现在诸如人名、地名、作品名的实体上时往往常规的纠错模型方案很难达到优异的表现,因为纠错模型的学习任务里不包含辨识实体的能力,而语料也不能覆盖所有可能的实体名,所以不免会出现在实体上的错纠或漏纠。
 图8 实体纠错示例
图8 实体纠错示例
以上方图8为例,第一条样例是把日本的地名[绳文杉]错纠成[绳文彬],这是因为模型不具备绳文杉是个地名的知识,而[文彬]的字词组合在模型输出中概率更高;第二条样例是漏纠了[格得战记]的错误,正确的作品名是[格德战记],这是因为模型学习语料中没有覆盖这个作品名称。为了解决实体误纠、漏纠的问题,我们训练了命名实体识别模型,模型结构是以Bert base (Devlin et al., 2019)加CRF的序列标注模型。预测时将实体词典和命名实体识别模型进行一定策略排布。
Ngram纠错方法
Ngram方法采用无监督方式纠错,即通过无标注语料训练n元语言模型,使用n元语言模型进行错误检测与纠正,通常认为ngram纠错方式在准确率方面效果一般,但结合过滤策略可在一定程度上提升准确率,即增强语义信息方面的检测,解其余方式带来的误纠。n元语言模型,一个语言模型构建字符串的概率分布P(W),假设P(W)是字符串作为句子的概率,则概率由下边的公式计算:

其中Wi表示句中第i个词。P(W4|W1W2W3)表示前面三个词是W1W2W3的情况下第四个词是W4的概率。W1W2W3...Wi-1称作历史,如果W共有5000个不同的词,i=3的时候就有1250亿个组合,但是训练数据或已有语料库数据不可能有这么多组合,并且绝大多数的组合不会出现,所以可以将W1W2W3...Wi-1根据规则映射到等价类,最简单的方式就是取Wi之前n-1个历史,根据马尔科夫假设,一个词只和他前面n-1个词相关性最高,这就是n元语言模型:
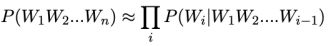
我们在无监督数据集中训练出该模型,并用比较高的阈值严格过滤结果,起到少召回的效果,在纠错系统的最终步骤完成对结果的补足。
数据集生成
由于先前提到的out of vocabulary对于纠错任务的严重影响,我们需要模型在尽可能大的数据集中进行训练。由此,需要使用混淆集在无标注数据下自动生成训练集。所有用到的混淆集和数据生成的代码均在项目文件中开源。我们使用的混淆集具体说明如下。
数据生成
针对未标注数据集,我们采用如下方法进行自动纠错对的生成。
- 使用分词算法将原句子进行分词处理。
- 使用序列标注模型对所有词语进行属性标注
- 对被序列标注模型所标注出的人名,地名类词语(如xx酒店,xx公司)进行不设错处理,即不会被替换为错字。同样被过滤的还有非中文词和停用词。
- 随机按比例抽取字词进行改动。如该词在混淆集中,15%不改动,15%概率随机改动,70%概率在混淆集中随机抽取改动。如该词不在混淆集中则不改动。
混淆集
关于近音字,在使用混淆集进行过滤任务时,我们采用以下算法进行近音字判定:考虑所有的多音字情况,当A字与B字所含拼音字母的差异小于2个,即判定为近音字。在使用混淆集进行生成任务时,则采用储备的混淆集直接进行替换。而关于近形字,由于先前对验证集数据的分析,我们认为绝大多数的错误都是音近或音近形近的错误,所以在使用混淆集进行生成任务时,我们没有使用形近字混淆集。而在过滤任务时则采用储备的形近字混淆集进行过滤
实验结果
依照比赛的要求,我们使用F1作为验证模型效果的指标,其中包括纠错F1和检测F1,并且分为句子和字词两个级别,其数据将以省略百分号(*100)的形式呈现。以下表1为模型在YACLC-CSC的测试集上的表现。值得注意的是,字词级别的Correlation F1只检查被模型检测到的错误,而不是所有错误。举例来说,假设模型只修改了一处错误,且修改正确,字词级别的Correlation F1将是100。
表1 各个方案实验结果对比
在如上表格中,Baseline是官方提供的基线模型;PYbert为加入拼音编码的基础模型;Multi-round为多轮纠错方法;Fluent为困惑度检测方法;NER为实体纠错方法;Ngram为Ngram纠错方法。在上述所有方法中,多轮纠错方法会增加召回数量,找到部分原先无法纠错的案例。困惑度检测则会减少召回的数量,将部分错误纠正的句子删除,但同时也会损失少量正确的句子。实体纠错方法则是针对所有实体进行再一次审查,将未正确纠错的实体正确纠错,将错误纠错的实体删除,准确率较高。最后,Ngram方法将补充未找到的案例,其召回数量很低(在该1100个句子的案例中只召回88条),所以不会删除错误召回。此方法的使用顺序大体基于模型的准确率(precision)。准确率较高而召回率(recall)较低的方法将放置于系统尾部,保证其输出的结果被删改的概率更低。如图所示,基础的拼音模型在经过生成数据的预训练和其余的微调过后,效果对比基线模型有大幅提升。而后,系统的每一个步骤都对Correlation F1的提升起到了帮助。
技术落地方案

图9 达观智能校对系统演示
达观智能校对系统依托于自然语言处理和光学字符识别等技术,实现了不同格式的输入文本的自动校对。该系统涵盖了内容纠错、格式纠错和行文规则纠错等针对不同应用场景下的纠错模块,其中内容纠错模块包括拼写纠错、语法纠错、领导人纠错、符号纠错和敏感词检测等多种校对模块。目前达观智能校对系统已支持公文领域、金融领域和通用领域的文本校对任务,并且可针对不同领域的校对需求为客户提供定制化的解决方案。系统概览如上图9所示。
本文的方法主要应用在文本纠错系统内容纠错中,包含别字纠错和别词纠错。除此之外,达观文本纠错系统还支持语法纠错,包括缺字,漏字,乱序,搭配错误等,可以进行输入句与输出句不同长度的纠错。纠错系统还针对公文等相关领域有增强策略。如领导人姓名,语录,行政区错误等。除了对文字内容的纠错检测,纠错系统对文本格式也能进行修正,包括抬头错误,文种错误,抄送机关错误等。
总结
文本提出了一种针对于中文拼写检查任务的纠错系统,并对其主要包含的五个部分进行了详细描述。并给出了该系统所进行的实验。在模型方面,我们提出了将拼音编码进Transformer Encoder的模型结果;针对于单句多错情况的多轮纠错方法;更加考虑句子整体性的混淆度检查方法;针对实体错误的实体纠错方法等。在数据方面,我们针对多音字进行数据增强,通过混淆集在巨量语料中自动生成正确-错误句子对。我们对于该系统进行了相关实验,验证了每个部分的有效性。并且介绍了模块在实际落地产品中的应用。
参考文献:
- Junshan Bao. nlp-fluency. https : / / github . com / baojunshan / nlp-fluency. 2021.
- Jacob Devlin et al. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”. In: Proceedings of the 2019 Conferenceof the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Minneapolis, Minnesota: Association for Computational Linguistics, June 2019, pp. 4171–4186. doi: 10.18653/v1/N19- 1423. url: https://aclanthology.org/N19-1423.
- DingminWang et al. “A Hybrid Approach to Automatic Corpus Generation for Chinese Spelling Check”. In: Proceedings of the 2018 Conferenceon Empirical Methods in Natural Language Processing (EMNLP). Brussels, Belgium, Nov. 2018.
- Pengcheng He et al. DeBERTa: Decoding-enhanced BERT with Disentangled Attention. 2020. doi: 10.48550/ARXIV.2006.03654. url: https://arxiv.org/abs/2006.03654.
- Piji Li and Shuming Shi. Tail-to-Tail Non-Autoregressive Sequence Prediction for Chinese Grammatical Error Correction. 2021. doi: 10.48550/ARXIV.2106.01609. url: https://arxiv.org/abs/2106.01609.
- Chao-Lin Liu et al. “Visually and Phonologically Similar Characters in Incorrect Simplified Chinese Words”. In: Coling 2010: Posters. Beijing, China: Coling 2010 Organizing Committee, Aug. 2010, pp. 739–747. url:https://aclanthology.org/C10-2085.
- Shulin Liu et al. “CRASpell: A Contextual Typo Robust Approach to Improve Chinese Spelling Correction”. In: Findings of the Association forComputational Linguistics: ACL 2022. Dublin, Ireland: Association forComputational Linguistics, May 2022, pp. 3008–3018. doi: 10 . 18653 /v1/2022.findings-acl.237. url: https://aclanthology.org/2022.findings-acl.237.
- Yuen-Hsien Tseng et al. “Introduction to SIGHAN 2015 Bake-off for Chinese Spelling Check”. In: Proceedings of the Eighth SIGHAN Workshop on Chinese Language Processing. Beijing, China: Association for Computational Linguistics, July 2015, pp. 32–37. doi: 10.18653/v1/W15-3106. url: https://aclanthology.org/W15-3106.1