背景
Image may be NSFW.
Clik here to view.
事实上,一个高效的A/B test在线实验平台已经成为各大互联网公司进行产品迭代和策略优化的标配工具。A/B测试是互联网公司实现数据驱动的基础,Microsoft、Google, Amazon、Facebook都在这方面做了大量的工作,腾讯、阿里、百度等国内主流互联网公司也纷纷各自构建了一套支持产品迭代和策略优化的A/B test在线实验平台。
Clik here to view.
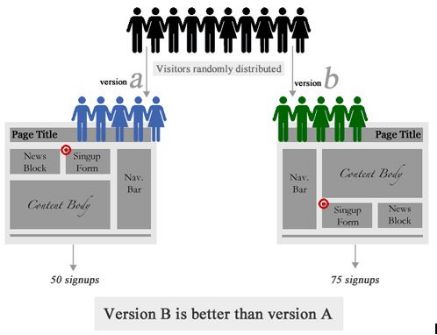
分层实验模型
Clik here to view.
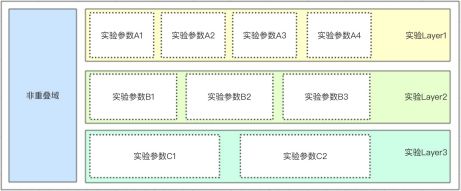
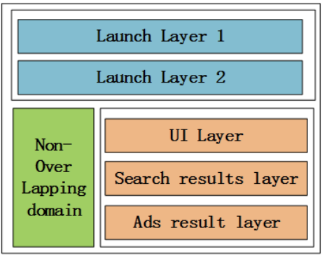
下图是一个更具体的栗子,左侧是非重叠域,右侧分为3层,分别是UI层、搜索结果层和广告结果层。
Clik here to view.
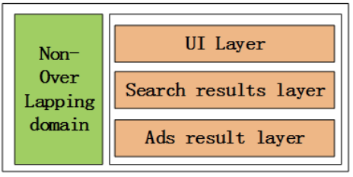
分层实验模型特性
特性1:纵向域划分,横向层划分。
特性2:相互关联的策略参数位于相同实验层,相互独立的策略参数位于不同实验层。
特性3:流量在不同实验层之间根据不同的分流策略被重新分配,不同层的实验流量是正交的。
特性4:不同实验层之间的实验相互独立。
特性5:模型的发布层(Launch Layers)可以实现实验流量的灰度发布直至全流量发布。
流量分配策略
策略1:随机分配
优点是简单自然,缺点是用户的请求会在不同参数集的实验中“穿梭”,造成用户体验上的不一致性。
策略2:按照cookie或用户id取模进行分配
此种流量划分方式可以确保用户的请求被分配到固定的实验中,不会造成用户体验的不一致。
策略3:按照cookie+日期取模进行分配
这种方式是综合了cookie和日期的信息后再取模,采用这种方式的话,一个实验一天内圈定的cookie是固定的,但随着日期的变更会圈定不同的cookie。
策略4:按照业务字段进行分配
这种方式可以满足特定的实验流量要求,比如可以按照用户的地域来源取特定城市的用户流量,或者按照用户年龄取特定年龄段的用户流量。
策略5:hash查询串取模进行分配
这种方式使得相同的查询串请求可以分流到确定的实验上。
为了保证层与层之间实验流量的相互独立,上述基于取模的流量分配策略需要考虑实验所在层layerid的信息, 假设当前层有20个bucket分桶(实验参数),则当前流量在当前层的bucket = (f(cookieid, layerid) % 20),f是某个hash函数。
Clik here to view.
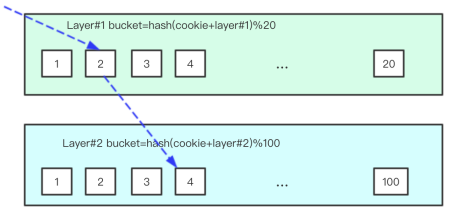
流量分流条件
灰度发布策略
1)创建一个实验或是一组实验来评估特性。注意配置实验涉及指定分配类型和相关的分配参数(比如:cookie取模),分配条件,和特性相关的参数。
2)评估实验指标。根据实验结果,判断是否要进行新一轮的实验,即通过修改或创建新的实验,或甚至修改代码从根本上改变特性。
3)如果特性可以发布,就进入发布过程:创建一个新的发布层和发布层实验,逐步的放量这个实验,并最终删除发布完的发布层,然后将发布层实验的相关参数设为系统默认参数。
Clik here to view.
Clik here to view.
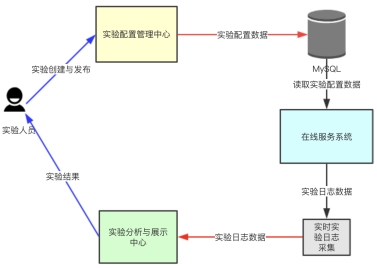
实验配置管理中心
实验创建:实验数据主要包括(但不限于)实验的名称(比如搜索Reranking实验)、实验的起始时间、实验owner、实验参数集、实验作用模块、流量分配等。其中实验起始时间定义了实验生效发生作用的时间范围,超过此时间实验自动结束并停止。实验参数集定义了需要测试的不同实验参数数据,每个实验参数对应实验的一个bucket分桶(比如rank_strategy=5, rank_strategy=6, rank_strategy=7分别对应实验的三个bucket)。每个实验都有一个唯一的实验ID。
实验流量分配:对实验选择流量划分策略(见前文介绍)。
实验启动:创建好的时间在达到实验设置的开始时间后自动启动,实验人员也可以对暂停的实验重新执行启动操作。
实验暂停:实验人员可以对执行中的实验执行暂停操作。
实验删除:实验人员可以删除已经停止的实验,正在执行的实验无法直接删除(需要先执行停止操作)
实验权限控制:实验的owner(创建者)对实验有启动、暂停、删除等权限,也即只能操作自己创建的实验。实验配置管理中心直接控制线上服务的模型和策略的执行,安全性就显得尤为重要。
实验持久化:实验的数据被存储到MySQL数据库中进行持久化。
实验分析与效果展示中心
Clik here to view.
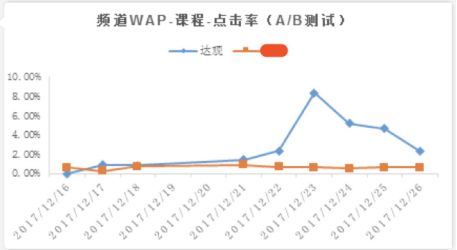
在我们的实践中,通过对实验日志数据的实时采集和分析,可以实现对实验效果(比如CTR指标)进行准实时的对比分析和监控。如果发现实验(新算法策略)的效果指标出现异常,可以在实验配置管理中心及时调整实验参数或调整实验流程或停止实验(达观数据桂洪冠)。
在线服务系统(实验执行环境)
职责1:定时从数据库中同步实验数据信息
职责2:实验流量决策。对每个请求流量,根据实验的流量划分策略进行bucket分桶计算,获取对应bucket的实验参数数据(策略和模型参数)。请求携带被分配的实验参数数据流入线上服务模块。
Image may be NSFW.
Clik here to view.
各线上服务模块从请求中获取自己关心的实验参数数据进行相应的实验,并在记录日志时把实验ID和参数数据一同写入。
总结
达观数据分层实验平台同时运行着数十个面向不同客户的多个系统应用的策略和模型迭代优化实验,已经成为公司基础平台体系架构中非常重要的组成部分。
未来展望
参考文献
1.Diane Tang, Ashish Agarwal, Deirdre O’Brien, Mike Meyer Overlapping Experiment Infrastructure: More, Better, Faster Experimentation
2.阿里妈妈大规模在线分层实验实践http://www.infoq.com/cn/articles/alimama-large-scale-online-hierarchical-experiment/
关于作者
桂洪冠,达观数据联合创始人,中国计算机学会CCF会员,自然语言处理技术专家。在参与创办达观数据前,曾在腾讯文学、阿里巴巴、新浪微博等知名企业担任数据挖掘高级技术管理工作。桂洪冠在数据技术领域拥有6项国家发明专利,中国科学技术大学计算机硕士学位。在大数据架构与核心算法以及文本智能处理等领域有深厚的积累和丰富的实战经验。