内容来源:ChatGPT 及大模型专题研讨会
分享嘉宾:中国科学院自动化研究所研究员 张家俊
分享主题:《ChatGPT中的提示与指令学习》
中国科学院自动化研究所研究员张家俊以ChatGPT中的提示与指令学习为题,从ChatGPT简要技术回顾、迈向通用性的提示学习、从提示学习到指令学习、相关探索与学习等角度和在场听众展开技术分享。大模型主要有两个方向,一个是“预训练+参数微调”,就是大模型有了之后针对下游任务进行微调,然后得到一个面向下游任务的大的模型,二是“预训练+提示学习”,预训练之后不变,用提示学习激发大模型来完成特定的任务。相关实践证明,学习提示对于模型性能提升非常有效,怎样学到或者找到提示语非常关键。下面是分享的详细内容。

ChatGPT简要技术回顾
一、基本介绍
ChatGPT不再仅仅是传统的人机对话系统。而是一个以自然语言为交互方式的通用语言处理平台。它在三个方面有非常优异的表现:首先,它在基础数据、核心模型和优化算法的技术实现上取得了重大突破;其次,它的应用非常接地气,几乎可以完成所有与语言相关的功能;最后,相比于过去的智能对话系统,它的交互体验效果产生了质的飞跃。
而超出预期的交互体验,又可以归功于四个关键能力:通用的意图理解能力、强大的连续对话能力、智能的交互修正能力以及较强的逻辑推理能力。这些能力一直以来对自然语言处理研究者来说属于高难度的任务,因为之前我们只是针对单个任务进行研究。然而随着ChatGPT的诞生和发展,我们现在认识到它可以实现更为复杂的任务。
二、ChatGPT的集成技术组成
ChatGPT是以产品思维驱动的重大集成创新成果,是OpenAI自2018年以来坚持生成式AI、长期技术积累,量变产生质变的重大成果,是迈向AGI的阶段性成果。
ChatGPT的集成技术主要包含三个方面:
- 基础模型架构。基础模型架构主要是生成式解码器,来自于Google2017年提出的Transformer[1]。
- 指令学习。同样来自于谷歌2021年提出的指令学习FLAN[2]。
- 基于人类反馈的强化学习。强化学习部分是OpenAI成立之后一直在专注的领域,2017年提出了强化学习的算法PPO[3],在2021年时它在自动摘要任务[4]上表现出非常好的性能,所以直接用到对话的场景上。
三、ChatGPT的基础大模型
ChatGPT的基础模型本质上是一个语言模型。语言模型做的事情,是给定前缀,预测下一个词是什么,或者说计算下一个词的可能性的分布,从中选择一个最优 的。而语言模型的训练过程本质是基于海量数据的自监督学习,通过对大量的文本进行学习。举个例子,对于“人工智能是模拟拓展人类智能的”这句话去预测下一个词是什么时,模型发现历史的文本里面,“人工智能的”后面有四次接了“理论”,三次接了“理论”,两次接了“技术”,所以预测时,模型会以更大的概率把结果预测为“理论”这个词,这个过程有点类似词语接龙。
对于语言模型来说,如果前面的上文历史信息能看得更长,预测就会更准确一些。每个输入的词都是以向量的方式来表示,每个词的表示维度越高,它的语义表示能力就越好。其次,主流的语言模型都是通过深度学习神经网络构建,它的网络层次越深,预测能力就越强。向量的表示维度和网络的层次,是影响参数规模的主要因素,参数规模越大,模型的容量就越高。从2018年-20201年,参数规模从1.17亿到1750亿,模型已经展现出来了巨大的变化,出现了能力涌现的特点。
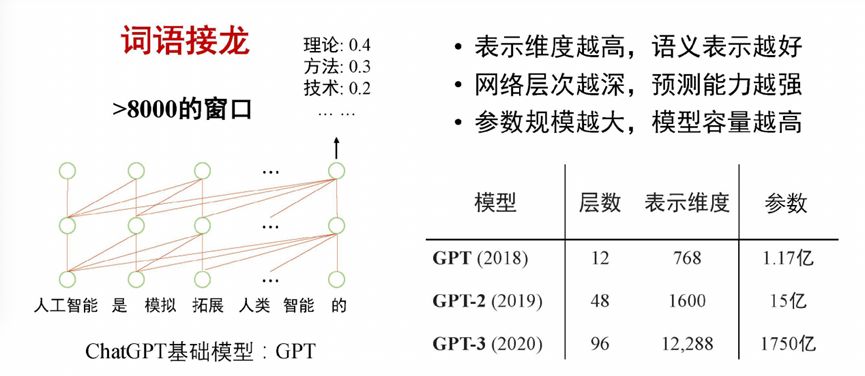 图 1 ChatGPT基础模型
图 1 ChatGPT基础模型
刚刚提到的能力涌现,意思是某些能力在参数规模较小的模型中不存在,在参数规模较大的模型中存在,则该能力就是涌现的。下图里面思维链的推理、新指令泛化会在100亿到1000亿的参数规模之间产生能力的涌现。
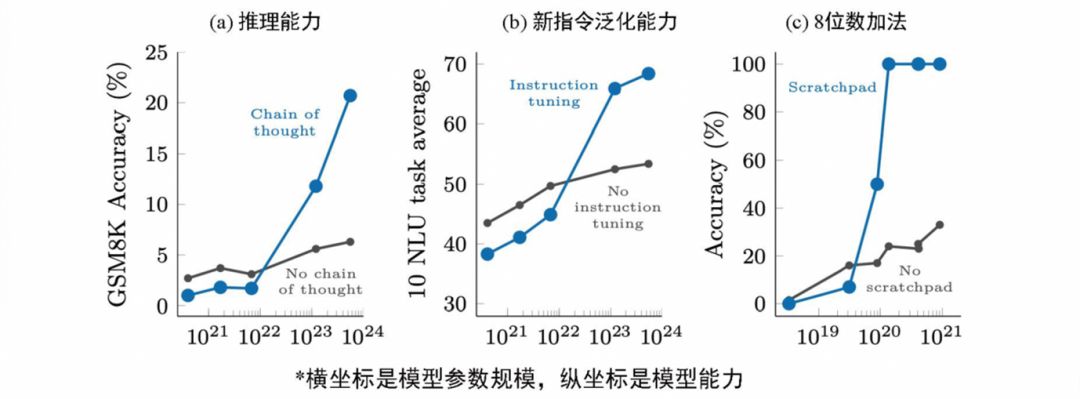 图 2 能力涌现
图 2 能力涌现
四、基于海量数据的自监督学习
ChatGPT基于海量数据的自监督学习来构建基础模型,这个过程不是一蹴而就的。在2020年,openAI使用45T文本数据训练得到了基础大模型GPT-3,实现了流畅性和知识性。能力体现上,GPT-3产生的文字流畅性比较高,但是通用任务的处理能力还没那么强。2021年,openAI在GPT-3的基础上,用179G代码数据通过自监督训练实现了逻辑编程模型CodeX,具备一定的推理能力。2022年,openAI利用更多更新文本数据和代码数据的混合学习,得到更强的基础大模型GPT-3.5,成为ChatGPT的基础模型,实现了流畅性、知识性和逻辑性(推理能力)。
在得到足够强大、能力足够通用的基础模型之后,ChatGPT还是用指令学习和基于人类反馈学习来进一步提升交互体验。其中指令学习指导模型能够遵循人类的指令来输出预期的内容,而基于人类反馈的强化学习则让模型更加符合人的偏好。ChatGPT通过把基础大模型、指令学习和基于人类反馈的强化学习结合起来,实现了流畅性、知识性、逻辑性和拟人性。
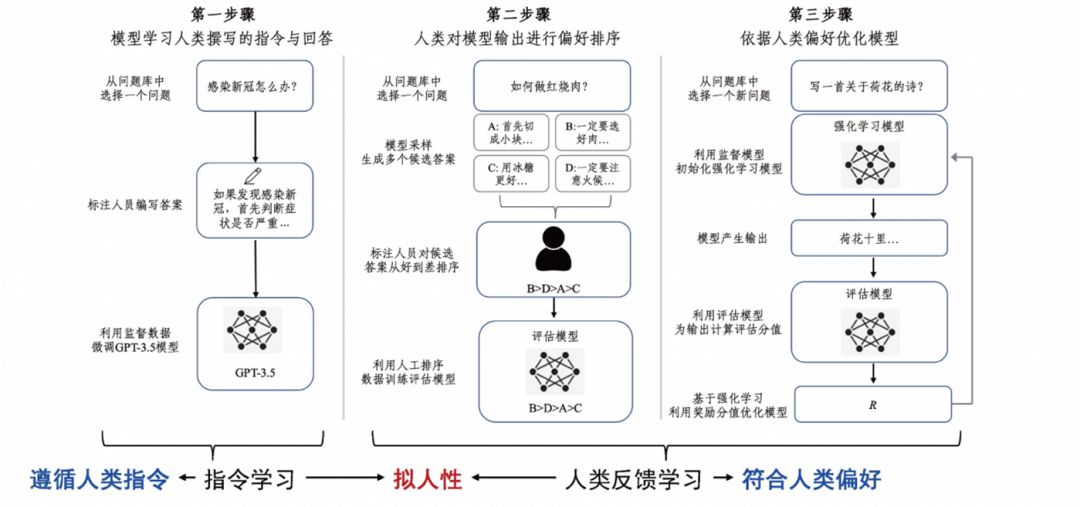 图 3 指令学习与人类反馈学习
图 3 指令学习与人类反馈学习
迈向通用性的提示学习
一、预训练大模型的两种方向
预训练大模型主要是通过“预训练+参数微调”(Pre-training+Fine-tuning)和“预训练+提示学习”(Pre-training+Prompt Learning)两种方式来实现下游任务的预测。
二、预训练+参数微调
“预训练+参数微调”是指大模型预训练后作为一个良好初始化的基础模型,从结构上适配每一个下游任务,并微调大模型的参数,使得下游任务的性能达到最优。譬如以大模型适应分类任务为例子,模型的实现方式是在预训练模型的最后一个节点增加一个简单的分类网络(softmax),在训练过程中,不仅去更新分类网络的参数,也去更新整个预训练模型的参数。训练完成后,模型就能更适合分类任务,不过与此同时,模型具有的通用性就变弱了。面向序列标注、文本生成任务也是采用预训练+参数微调的方式来更新模型参数,模型的通用能力也会减弱。同样的情况可以推广到机器翻译、自动问答、情感分析的任务。
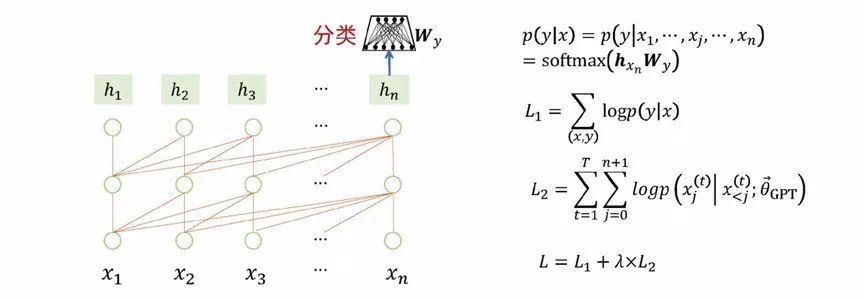
图 4 预训练+参数微调:适应分类任务
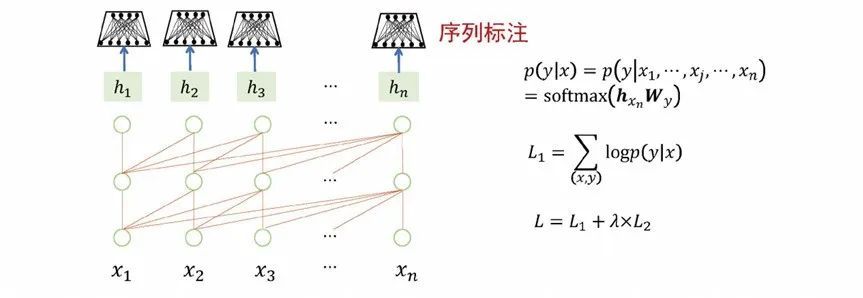
图 5 预训练+参数微调:适应分序列任务
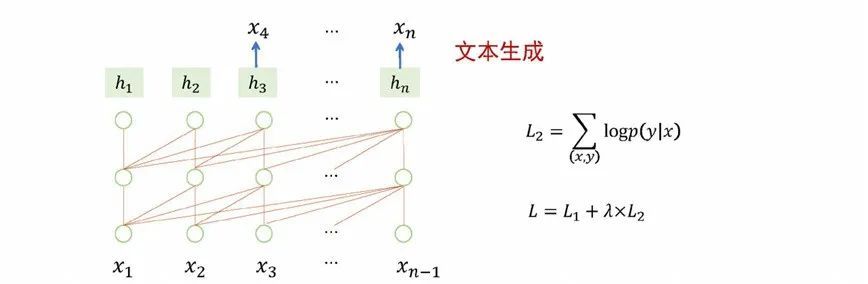
图 6 预训练+参数微调:适应文本生成任务
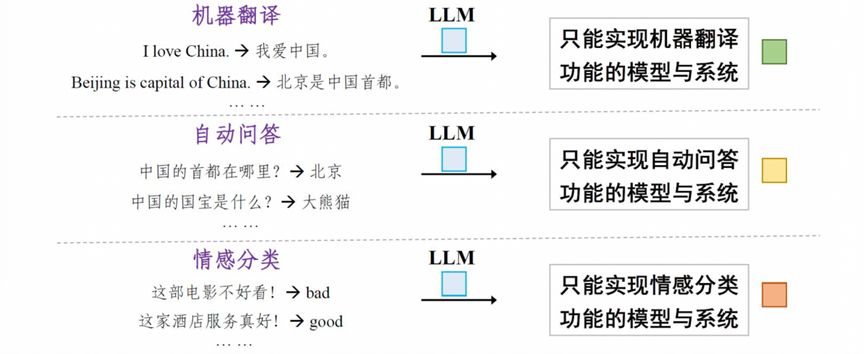
图 7 “预训练+参数微调”范式
从上面这些例子做个总结,预训练+参数微调的方式能够在特定任务取得不错的效果,不过这种方式存在一些局限性。第一,预训练+参数微调的方式缺乏处理通用问题的能力。第二,需要针对每种任务都独立进行模型训练,资源占用过多。第三,会存在过拟合的问题,因为不是所有类型的任务都有大量的标注数据,在下游任务数据少的情况存在泛化能力方面的问题。
三、预训练+提示学习
“预训练+提示学习”指的是先对大型模型进行预训练,在后续的任务中保持参数不变,利用提示语的形式使预训练模型能够满足各种下游任务需求。具体来说,我们会将下游任务转换为预训练模型的输入输出格式,例如文本分类、序列标注和文本生成等任务都需要将文本输入格式化为预训练模型的输入格式,并将预训练模型的输出转换为任务需要的输出格式,最终通过利用提示语激活大模型来完成特定任务。
我们针对几个常见的NLP任务来描述一下预训练+提示学习的处理过程。譬如有个文本分类场景要对“I truly love this film”这句评论来预测它表达的情感倾向是“positive”或“negative”。提示学习的处理办法是在“I truly love this film”句子后面加个提示语“Its sentiment is”,用语言模型来预测下一个词是什么,预测结果如果为“positive”或“negative”则可以作为最终预测结果,或者如果两个词都没命中,可以通过判断“positive”还是“negative”的概率更高,来完成整个任务的处理。其他的任务的处理过程是类似的,主要在于提示语有所区别。在处理词性标注时,是在句子后面添加提示语“Its POS is”,然后就按照语言模型的方式生成词性标注结果。在处理翻译的时候,是在句子后面添加提示语“Its Chinese Translation is”,然后语言模型会预测输出“我真的喜欢这部电影”。
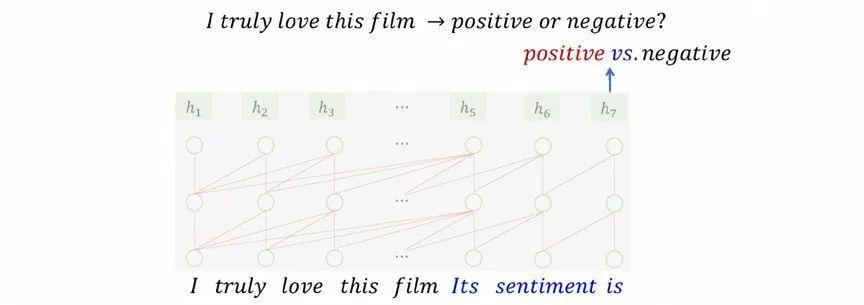 图 8 预训练+提示学习:分类任务适应大模型
图 8 预训练+提示学习:分类任务适应大模型
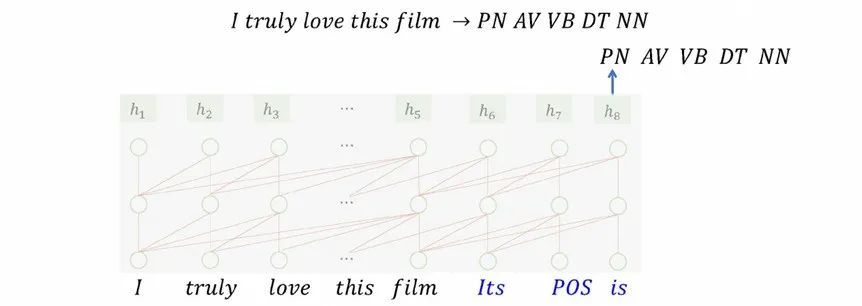 图 9 预训练+提示学习:序列标注任务适应大模型
图 9 预训练+提示学习:序列标注任务适应大模型
 图 10 预训练+提示学习:文本生成任务适应大模型
图 10 预训练+提示学习:文本生成任务适应大模型
四、提示语
提示语是预训练+提示学习里面的重要要素。怎么理解提示语呢,提示语就是插入到下游任务文本输入中的一段特殊文本,可以视为一组特殊参数,触发预训练大模型实现特定下游任务的同时,保持预训练大模型训练和测试一致。
提示语可以是离散的,也可以是连续的。离散的提示语比较常见,上面提及的提示语就是离散提示语。离散提示语的产生主要有两种方式:人工分析特定的下游任务,总结下游任务的规律,设计适合特定下游任务的提示语;通过从文本数据中自动搜索的方式找到合适的完成特定下游任务的提示语。为每个任务每个样本找到合适的提示语是一个巨大挑战,不同提示语导致显著的结果差异。
连续提示语则是在输入文本或者模型中加入一组连续向量代表具有泛化能力的提示语。连续提示语有两种添加方式,一种是直接在文本输入前添加[5],一种是网络或者每层网络前添加连续向量表示提示语[6]。
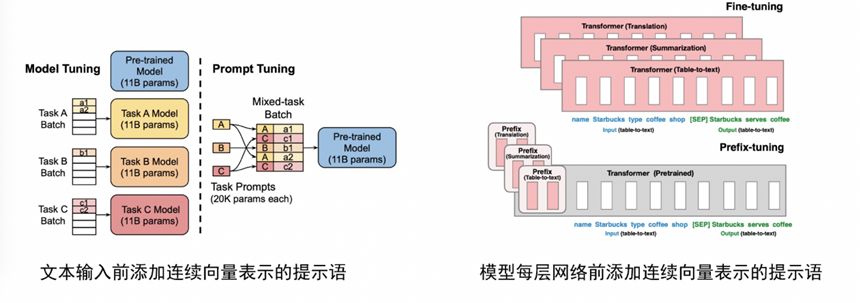 图 11 连续提示语
图 11 连续提示语
五、对比分析
我们对“预训练+参数微调”和“预训练+提示学习”两种方式进行对比。
两种方式最重要的区别是在支持下游任务的形式[7]。下图中“预训练+参数微调”的大模型需要针对不同任务来对参数进行调整,“预训练+提示学习”只需要通过设计提示信息来修改输入模式,使得让它具有完成下游任务的能力。
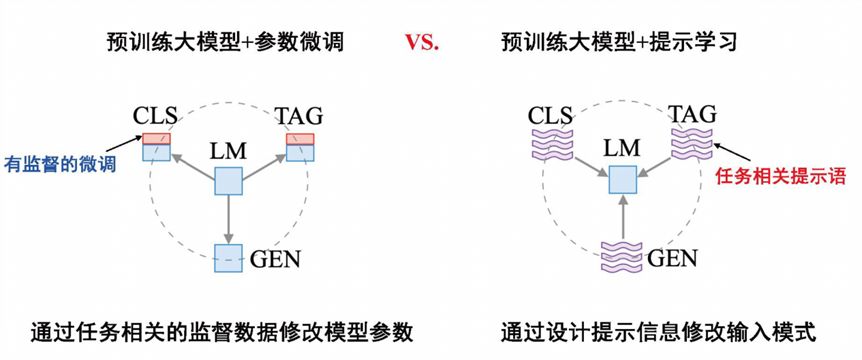 图 12 “预训练+参数微调” VS “预训练+提示学习”
图 12 “预训练+参数微调” VS “预训练+提示学习”
虽然“预训练+提示学习”有显著的优点,不过在2020年前相关方向的研究成果较少。这是因为之前的模型规模较小、通用性比较弱,不适合提示学习,适合参数微调。而到了2020年后,模型规模有大幅提升,微调的成本也随之提升,同时通用性强,适合提示学习。
 图 13 从“预训练+参数微调”到 “预训练+提示学习”
图 13 从“预训练+参数微调”到 “预训练+提示学习”
下图的蓝线是GPT-3在45个任务上的Zero Shot性能,准确率平均在30%左右,效果还是比较弱的。这说明提示学习能够触发预训练大模型完成特定任务,但是单一的外部提示信号难以最大限度地激发预训练大模型的能力,从而高质量地完成具体任务。
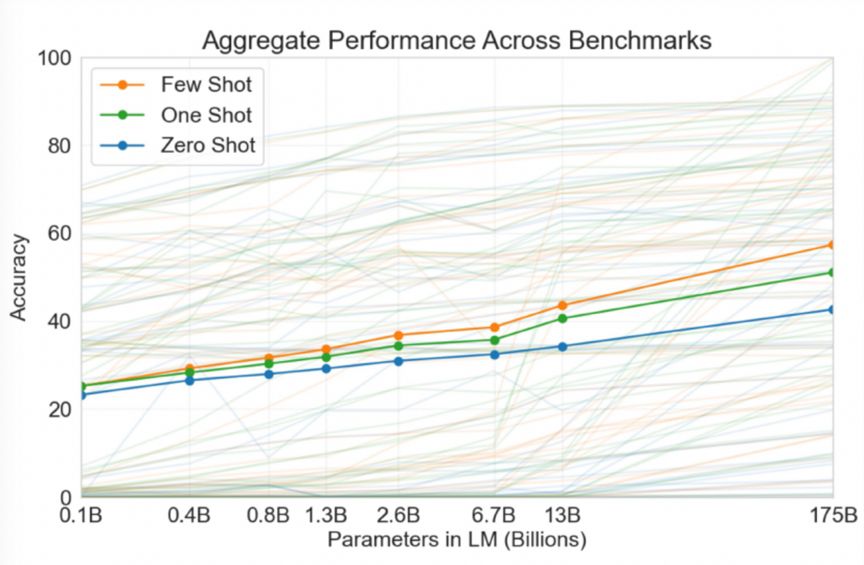 图 14 GPT-3在45个任务上的性能
图 14 GPT-3在45个任务上的性能
从提示学习到指令学习
“预训练+参数微调”通过具体任务的监督数据微调模型参数,能够最大限度地激发预训练大模型完成特定任务的能力,但是面临数据稀缺、灾难遗忘、资源浪费、通用性弱等难题。“预训练+提示学习”通用性强,但是在具体任务上效果偏弱。所以研究者考虑更好整合两者的优势,让大模型更好理解具体任务的执行意图,所以就有了从提示学习到指令学习的过渡。“参数微调”、“提示学习”、“指令学习”的执行逻辑如下:
- 大模型+参数微调:通过任务相关的通过设计提示通过若干任务相关的经过提示监督数据修改模型参数。
- 大模型+提示学习:通过设计提示通过若干任务相关的经过提示监督数据修改模型参数信息修改输入模式。
- 大模型+指令学习[8][9]:通过若干任务相关的经过提示增强的监督数据优化模型参数。
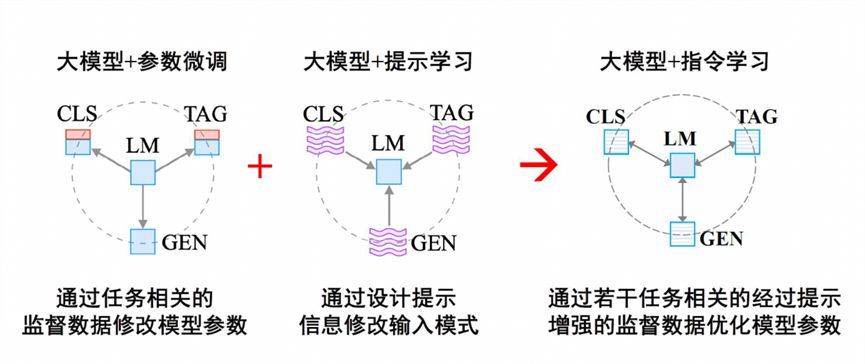 图 15 大模型+指令学习
图 15 大模型+指令学习
下面看一个提示学习的例子,还是以机器翻译、问答和情感分类作为任务场景,原来是每个任务场景对应一个模型,现在把所有任务的形式转变为语言模型的形式。譬如处理翻译任务时,把提示语的信息插入文本得到“‘I love China’的中文翻译是”。不同的样本可以使用不同的提示语来保证一定差异性。然后把所有任务的标注数据合并在一起,作为一个统一的任务执行参数微调。所有数据经过训练之后得到一个新的大模型,新的大模型可以再利用提示语触发大模型去完成特定的能力,结果是能够支持不同任务的同时也提升了多任务的执行效果。
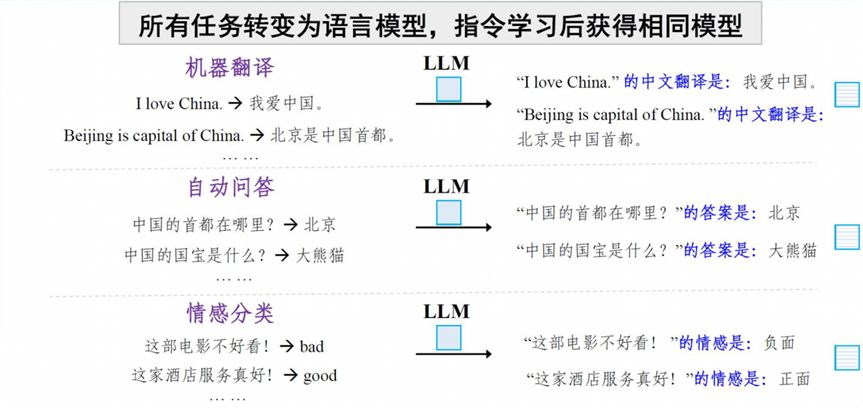
图 16 “大模型+指令学习”适应下游任务
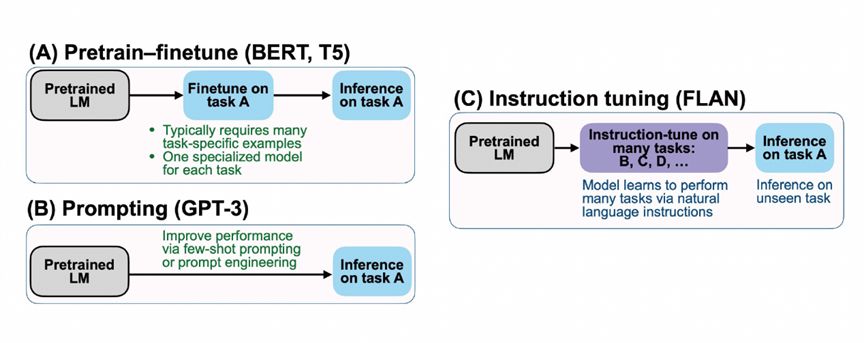 图 17 谷歌FLAN模型
图 17 谷歌FLAN模型
这是当时谷歌提出来FLAN的例子,左上角是预训练+微调,左下角是提示语,右边是FLAN的指令学习,是前两者的结合。FLAN在数十个任务上微调,发现它在未见的任务上也有预测能力。举例来说,FLAN在对常识推理、翻译等任务进行微调后,会发现训练好的模型会在自然语言推断任务上具备不错的预测效果。所以FLAN在62个数据集40多个任务上进行了训练,任务包含理解和生成两种形态。实验结果发现当参数达到百亿规模以上,几十个任务的联合指令学习就可以解决未知的任务。
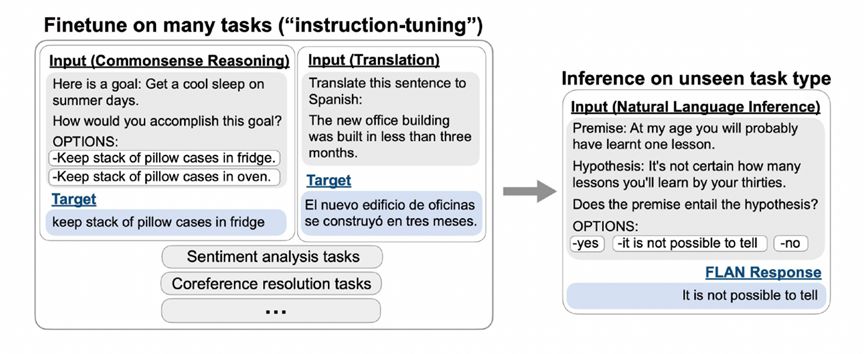 图 18 FLAN展现的未知任务的预测能力
图 18 FLAN展现的未知任务的预测能力
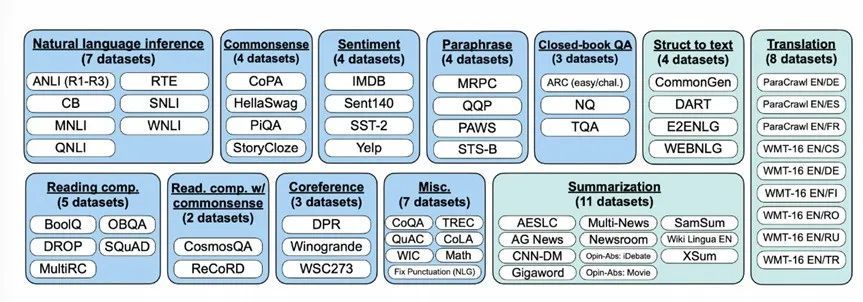 图 19 FLAN使用的文本任务数据集
图 19 FLAN使用的文本任务数据集
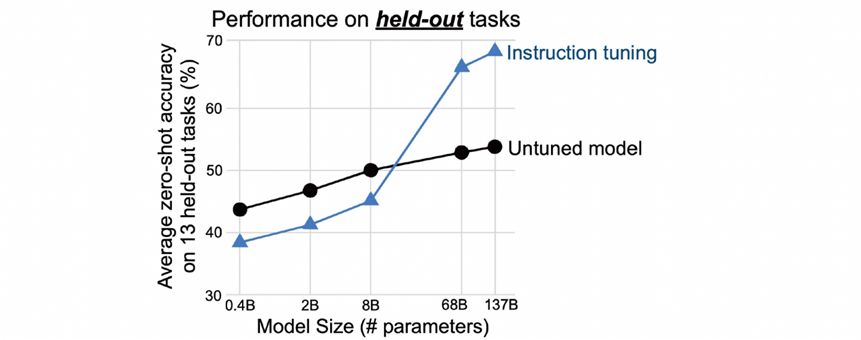 图 20 百亿参数规模模型多任务联合学习可以解决未知任务
图 20 百亿参数规模模型多任务联合学习可以解决未知任务
FLAN的重大发现对后续的工作起到了指导作用。在此基础上,ChatGPT的前身Instruct GPT收集了API指令,这样它的指令 类型更丰富,覆盖的范围越大,在此基础上的训练更触发了它的通用能力。
大语言模型的相关探索和实践
一、如何寻找最佳的提示语
上文提示学习的内容提到,提示语对预测效果有显著影响。下面的例子展示了ChatGPT在处理同样的文本翻译时,采用了不同的提示词(“中文翻译是什么”和“用中文怎么说”),返回的结果差异非常大。此时如何提升模型效果的问题可转化为,如何找到不同问题的最佳提示语,有没有一种方法自动学习提示语。
 图 21 不同提示语对文本翻译结果的影响
图 21 不同提示语对文本翻译结果的影响
二、样本级提示学习方法
针对上述问题,我们提出一种样本级提示学习方法[10],为每个样本学习最合适的提示语。执行的方式为,来了新的样本时,模型会结合输入的提示语和文本,根据相关性去搜索最相关的提示语,作为语言模型的输入。这种方法的优势是最大限度地建模了不同样本的独特性,相比于相同的提示语取得更好的性能提升,不过存在的不足之处是未考虑样本间的共性,也即忽略了不同的样本实际上属于同一种任务的事实。
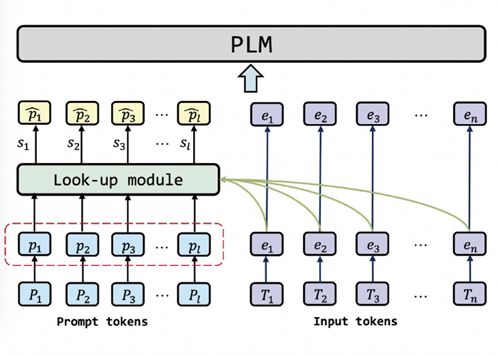
图 22 样本级提示学习方法
三、统一提示学习方法
鉴于样本级提示学习方法只考虑样本、没有考虑到任务的共性,所以我们进一步提出了统一提示语学习的方法[11],可以同时建模任务级的信息和样本级的信息。它的处理办法是为每个任务学习一个提示,为任务中的每个样本学习一个提示,两类提示信息进行融合,获得最佳提示。下图是统一提示学习方法的架构,灰色的部分参数不变,蓝色的部分是非常小的参数量,一个是从样本学到样本级的参数,一个是每个任务有对应的参数。通过这个结构模型能够判断每个样本应该用多少任务级的信息、多少样本级的信息,最终为每个样本学到最合适的提示。
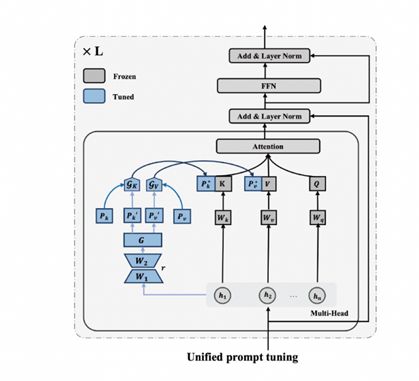
图 23 统一提示学习方法
统一提示学习方法优势是同时结合了任务信息和样本信息,理论上可以获得最佳的提示信息。存在的不足是需要提前知道任务信息,需要进一步的泛化。相比之下目前ChatGPT在不知道请求的任务是什么的情况,也能够感知到任务的具体类型,有较大优势。后续研究拓展方向可以通过感知的方式判断任务的信息,在跟任务信息已知的基础上再去学习任务和样本相关的泛化。
四、实验效果
实验结果验证了统一提示学习方法在SuperGLEU标准数据集上取得少样本学习的最佳平均性能。在SuperGLEU数据集上发现,统一提示学习方法比GPT-3在上下文推理能力能力更优(单句子任务的平均任务得分分别为83.2和70.0,句子对相关任务的平均得分为72.0和49.8),这说明了学习提示对提升模型效果非常有效,如何找到最佳提示语非常关键。
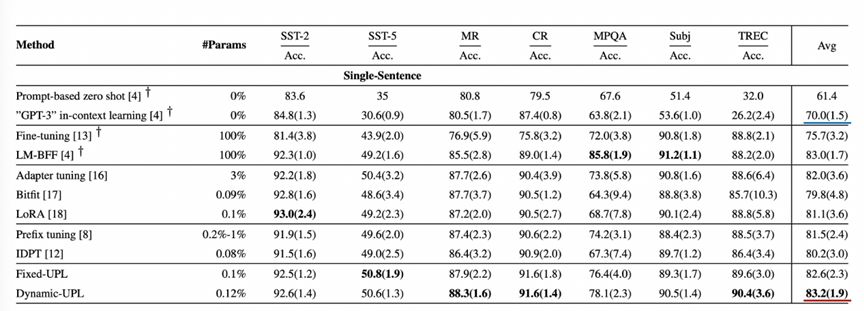
图 24 统一提示学习方法在SuperGLEU标准数据集单句子任务上的效果
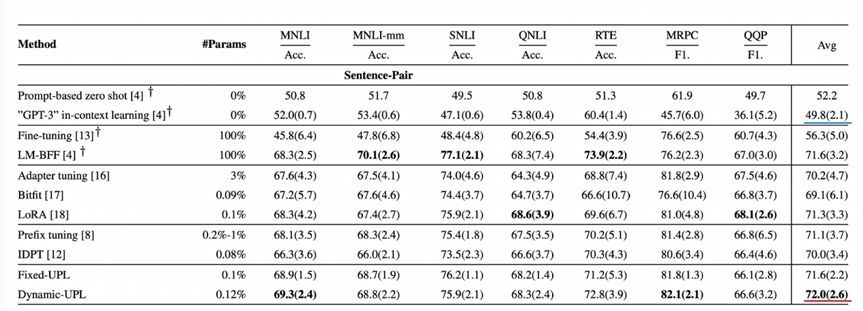 图 25 统一提示学习方法在SuperGLEU标准数据集双句子任务上的效果
图 25 统一提示学习方法在SuperGLEU标准数据集双句子任务上的效果
开放性问题思考
一个月前写了《ChatGPT八个技术问题的猜想》,后来一直在做模型探索,整理了一些开放性问题与观众读者探讨:
第一,实践发现数据不仅仅决定模型性能,还能极大影响模型训练过程的成败,其中的原因是什么。Meta去年发布几个模型,在训练过程中失败挂掉了二十多次,每一次数据会影响数据的训练是否成功。
第二,能力涌现是如何发生的?为什么会在百亿参数规模以上才会体现出来?或者并非涌现,只是模型规模测试不够连续。
第三,中文等语言的数据占比非常少,例如只有不到5%,而模型的中文表现却非常好?能力迁移是如何发生的。
第四,大模型的能力能否蒸馏到小模型。
第五,作为黑盒的通用大模型似乎与人脑有相似之处,未来是否可以采用脑科学研究范式研究大模型。
参考文献
[1] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
[2] Wei J, Bosma M, Zhao V Y, et al. Finetuned language models are zero-shot learners[J]. arXiv preprint arXiv:2109.01652, 2021.
[3] Schulman J, Wolski F, Dhariwal P, et al. Proximal policy optimization algorithms[J]. arXiv preprint arXiv:1707.06347, 2017.
[4] Von Rueden L, Mayer S, Beckh K, et al. Informed Machine Learning–A taxonomy and survey of integrating prior knowledge into learning systems[J]. IEEE Transactions on Knowledge and Data Engineering, 2021, 35(1): 614-633.
[5] Lester B, Al-Rfou R, Constant N. The power of scale for parameter-efficient prompt tuning[J]. arXiv preprint arXiv:2104.08691, 2021.
[6] Li X L, Liang P. Prefix-tuning: Optimizing continuous prompts for generation[J]. arXiv preprint arXiv:2101.00190, 2021.
[7] Liu P, Yuan W, Fu J, et al. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing[J]. ACM Computing Surveys, 2023, 55(9): 1-35.
[8] Wei J, Bosma M, Zhao V Y, et al. Finetuned language models are zero-shot learners[J]. arXiv preprint arXiv:2109.01652, 2021.
[9] Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback[J]. Advances in Neural Information Processing Systems, 2022, 35: 27730-27744.
[10] Jin F, Lu J, Zhang J, et al. Instance-aware prompt learning for language understanding and generation[J]. arXiv preprint arXiv:2201.07126, 2022.
[11] Jin F, Lu J, Zhang J,et al. Unified prompt learning makes pre-trained language models better few-shot learners. ICASSP 2023.