PRML读书会第八章 Graphical Models
主讲人 网神
(新浪微博: @豆角茄子麻酱凉面)
网神(66707180) 18:52:10
今天的内容主要是:
1.贝叶斯网络和马尔科夫随机场的概念,联合概率分解,条件独立表示;2.图的概率推断inference。
图模型是用图的方式表示概率推理 ,将概率模型可视化,方便展示变量之间的关系,概率图分为有向图和无向图。有向图主要是贝叶斯网络,无向图主要是马尔科夫随机场。对两类图,prml都讲了如何将联合概率分解为条件概率,以及如何表示和判断条件依赖。
先说贝叶斯网络,贝叶斯网络是有向图,用节点表示随机变量,用箭头表示变量之间的依赖关系。一个例子:

这是一个有向无环图,这个图表示的概率模型如下:
p(x1,x2,…x7)= 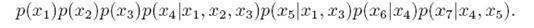 形式化一下,贝叶斯网络表示的联合分布是:
形式化一下,贝叶斯网络表示的联合分布是:
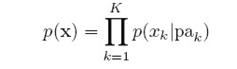
其中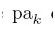 是xk的所有父节点。
是xk的所有父节点。
以上是贝叶斯网络将联合概率分解为条件概率的方法,比较直观易懂,就不多说了。下面说一下条件独立的表示和判断方法。条件独立是,给定a,b,c三个节点,如果p(a,b|c)=p(a|c)p(b|c),则说给定c,a和b条件独立。当然 a, b, c也可以是三组节点,这里只以单个节点为例。用图表示,有三种情况 。
第一种情况如图:
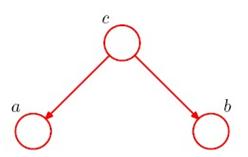
c位于两个箭头的尾部,称作tail-to-tail,这种情况,c未知的时候,a,b是不独立的。c已知的时候,a,b条件独立。来看为什么,首先,这个图联合概率如下:
在c未知的时候,p(a,b)如下求解:
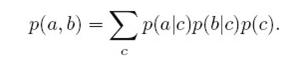
可以看出,无法得出:p(a,b)=p(a)p(b),所以a,b不独立。
如果c已知,则:
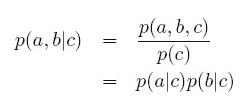
所以a,b条件独立于c。条件独立用以下符号表示:
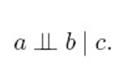
a,b不独立的符号表示::
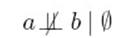
这是图表示的条件独立的第一种形式,叫做tail-to-tail。第二种是tail-to-head,如图:
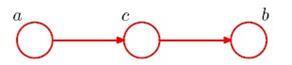
这种情况也是c未知时,a和b不独立。c已知时,a和b条件独立于c,推导如下:
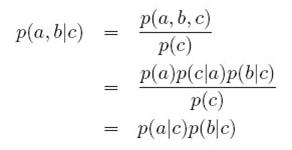
第三种情况是head-to-head,如图:
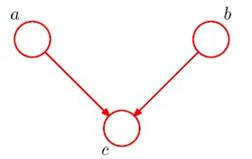
这种情况反过来了,c未知时,a和b是独立的;但当c已知时,a和b不满足条件独立,
因为: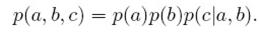
计算该概率的边界概率,得
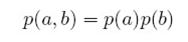
所以a和b相互独立.
但c已知时:
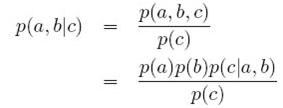
无法得到p(a,b|c)=p(a|c)p(b|c)
将这三种情况总结,就是贝叶斯网络的一个重要概念,D-separation,这个概念的内容就是:
A,B,C三组节点,如果A中的任意节点与B的任意节点的所有路径上,存在以下节点,就说A和B被C阻断:
1, A到B的路径上存在tail-to-tail或head-to-tail形式的节点,并且该节点属于C
2. 路径上存在head-to-head的节点,并且该节点不属于C
举个例子:
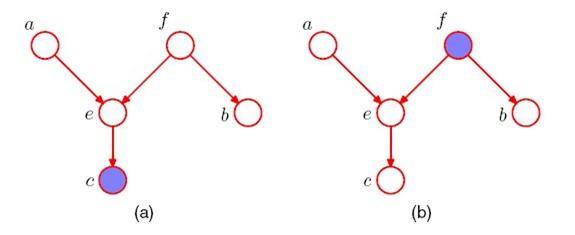
左边图上,节点f和节点e都不是d-separation.因为f是tail-to-tail,但f不是已知的,因此f不属于C.
e是head-to-head,但e的子节点c是已知的,所以e也不属于C。
speedmancs<speedmancs@qq.com> 19:23:05
2漏了一点,该节点包括所有后继
网神(66707180) 19:23:21
右边图,f和e都是d-separation.理由与上面相反.对,是漏了这一点。看到这个例子才想起来,这部分大家有什么问题没?
speedmancs<speedmancs@qq.com> 19:24:54
这个还是抽象了一些,我之前看的prml这一章,没看懂,后来看了PGM前三章,主要看了那个学生成绩的那个例子,就明白了。姑妄记之,其实蛮不好记的。讲得挺好的,继续。
网神(66707180) 19:27:14
因为有了这些条件独立的规则,可以将图理解成一个filter。
既给定一系列随机变量,其联合分布p(x1,x2…,xn)理论上可以分解成各种条件分布的乘积,但过一遍图,不满足图表示依赖关系和条件独立的分布就被过滤掉。所以图模型,用不同随机变量的连接表示各种关系,可以表示复杂的分布模型。
接下来是马尔科夫随机场,是无向图,也叫马尔科夫网络,马尔科夫网络也有条件独立属性。
用MRF(malkov random field)表示马尔科夫网络,MRF因为是无向的,所以不存在tail-to-tail这些概念。MRF的条件独立如图:
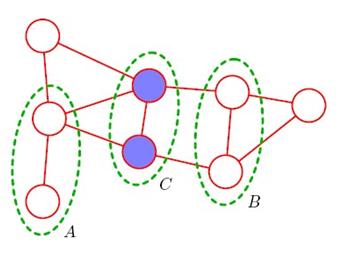
如果A的任意节点和B的任意节点的任意路径上,都存在至少一个节点属于C
speedmancs<speedmancs@qq.com> 19:33:16
无向图的条件独立 比有向图简单多了。
网神(66707180) 19:33:18
那么A和B条件独立于C,可以理解为,如果C的节点都是已知的,就阻断了A和B的所有路径。
网神(66707180) 19:33:49
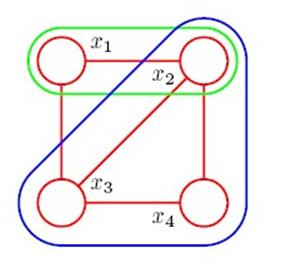
嗯,MRF的 概率分解就概念比较多了,不像有向图那么直观,MRF联合概率分解成条件概率。用到了clique的概念,我翻译成”团”,就是图的一个子图,子图上两两节点都有连接. 例如这个图,最大团有两个,分别是(x1,x2,x3)和(x2,x3,x4):
MRF的联合概率分解另一个概念是potential function,联合概率分解成一系列potential函数的乘积:
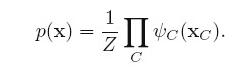
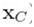 是一个最大团的所有节点,一个potential函数
是一个最大团的所有节点,一个potential函数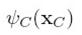 ,是最大团的一个函数.
,是最大团的一个函数.
这个函数具体的定义是依赖具体应用的,一会举个例子.
上面式子里那个Z是normalization常量:
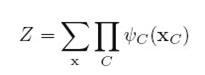
speedmancs<speedmancs@qq.com> 19:42:47
这个Z很麻烦
网神(66707180) 19:43:15
在这个式子里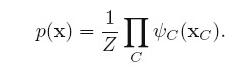 ,p(x)是一系列potential函数的乘积。换一种理解方式,定义将potential函数表示成指数函数:
,p(x)是一系列potential函数的乘积。换一种理解方式,定义将potential函数表示成指数函数:
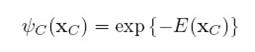
这样p(x)就可以表示成一系列E(Xc)的和的指数函数,E(Xc)叫做能量函数,这么转换之后,可以将图理解成一个能量的集合,他的值等于各个最大团的能量的和.先举个例子看看potential函数和能量函数在具体应用中是什么样的,大家再讨论。
要把噪声图片尽量还原成 原图,用图的方式表示噪声图和还原后的图,每个像素点是一个节点:
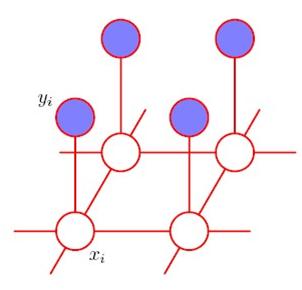
上面那层Yi,是噪声图,紫色表示这些是已知的,是观察值。下面那层Xi是未知的,要求出Xi,使Xi作为像素值得到的图,尽量接近无噪声图片。每个xi的值,与yi相关,也与相邻的xj相关。这里边,最大团是(xi, yi)和(xi, xj),两类最大团。
对于(xi, yi),选择能量函数E(xi,yi)=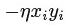 ;对于(xi,xj),选择能量函数E(xi, xj)=
;对于(xi,xj),选择能量函数E(xi, xj)=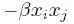
两个能量函数的意思都是,如果xi和yi (或xi和xj)的值相同,则能量小;如果不同,则能量大.
整个图的能量如下:
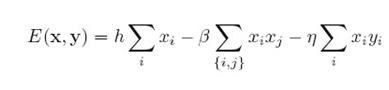
 是一个偏置项
是一个偏置项
speedmancs<speedmancs@qq.com> 19:56:55
偏置项是一种先验吧
网神(66707180) 19:57:28
有了这个能量函数,接下来就是求出Xi,使得能量E(x,y)最小。求最小,书上简单说了一下,我的理解也是用梯度下降类似的方法。
speedmancs<speedmancs@qq.com> 19:57:34
这里表示-1的点更多吧。
网神(66707180) 19:58:20
对偏执项的作用,书上这么解释:Such a term has the effect of biasing the model towards pixel values that have one particular sign in preference to the other.
speedmancs<speedmancs@qq.com> 19:59:29
恩,对,让能量最小
网神(66707180) 19:59:39
为了使E(x,y)尽量小,是尽量让xi选择-1,而不是1。E(x,y)越小,得到的图就越接近无噪声的图,因为:

所以E(x,y)越小,p(x,y)就越大。
η<liyitan2144@163.com> 20:01:13
是不是可以这样看,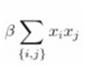 表示平滑;
表示平滑;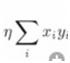 表示似然。
表示似然。
网神(66707180) 20:02:18
liyitan2144说得好,
speedmancs<speedmancs@qq.com> 20:02:33
恩,所以这是一个 产生式模型。
网神(66707180) 20:02:59
有向图和无向图的概率分解 和 条件独立 都说完了.有向图和无向图是可以互相转换的,有向图转换成无向图,如果每个节点都只有少于等于1个父节点,比较简单。如果有超过1个父节点,就需要在转换之后的无向图上增加一些边,来避免都是有向图上的一些关系,这部分就不细说了。
下面要说图的inference了。前面大家有啥要讨论的?先讨论一下吧。
============================讨论=================================
speedmancs<speedmancs@qq.com> 20:06:45
刚才那个例子中,那几个beta, h等参数如何得到?
网神(66707180) 20:07:30
那个是用迭代求解的方法,求得这几个参数,书上提到了两种方法,一种ICM,iterated conditional modes
一种max-product方法,其中max-product方法效果比较好,在后面的inference一节里详细讲了这个方法,而ICM方法只是提了一下,原理没有细说.两种方法的效果看下图,左边是ICM的结果,右边是max-product的方法:

speedmancs<speedmancs@qq.com> 20:15:07
稍微插一句,刚才那个denoise的例子,最好的那个结果是graph cut,而且那几个beta参数是事先固定了。
η<liyitan2144@163.com> 20:16:12
graph cut是指?
kxkr<lxfkxkr@126.com> 20:16:30
 kxkr<lxfkxkr@126.com> 20:17:18
kxkr<lxfkxkr@126.com> 20:17:18

网神(66707180) 20:18:11
这个例子只是为了说明能量函数和潜函数.所以不一定是最佳方法,这两段截屏是prml上的,咋没看到捏
kxkr<lxfkxkr@126.com> 20:19:05
那几个参数如何得到 文中好像并没有说,只是说了ICM、graph-cut能够得到最后的去噪图像,第一段 在 figure8.30,第二个截图在 section8.4,figure8.32下面。
网神(66707180) 20:20:15
看到了,先不管这个吧,主要知道能量函数是啥样的就行了
kxkr<lxfkxkr@126.com> 20:21:25
嗯
========================讨论结束==============f===================
网神(66707180) 20:22:24
接着说inference了,inference就是已知一些变量的值,求另一些变量的概率

比如上图,已知y,求x的概率
这个简单的图可以用典型的贝叶斯法则来求
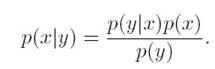
对于复杂点的情况,比如链式图:
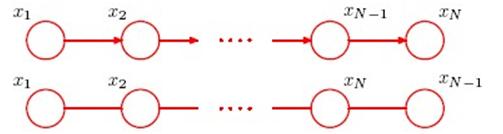
为了求p(xn),就是求xn的边界概率。这里都假设x的值是离散的。如果是连续的,就是积分,为了求这个边界概率,做这个累加动作,如果x的取值是k个,则要做k的(N-1)次方次计算,利用图结构,可以简化计算,这个简化方法就不讲了。
下面讲通用的图inference的方法,就是factor graph方法,链式图或树形图,都比较好求边界概率。
所以factor graph就是把复杂的图转换成树形图,针对树形图来求.先说一下什么是树形图,树形图有两种情况:
1. 每个节点只有一个父节点。
2. 如果有的节点有多个父节点,必须图上每个节点之间只有一条路径。
这是树形图的三种情况:
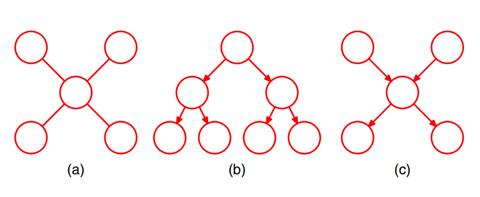
对于无向图,只要无环,都可以看做树形图;对于有向图,必须每两个节点之间只有一条路径;中间那种是典型的树.右边那种多个有多个节点的叫polytree。
这种书结构的图,都比较好求边界概率. 具体怎么求,就不说了。
这里主要说怎么把复杂的图转换成树形图.,这种转换引入factor节点,从而将普通的图转换成factor图.
先看个例子:
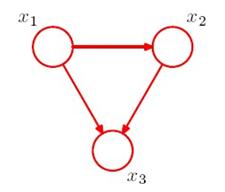
对于这个有向图,p(x1,x2,x3)=p(x1)p(x2|x1)p(x3|x1,x2),等号右边的三个概率作为三个factor
每个factor作为一个节点,加入新的factor图中:
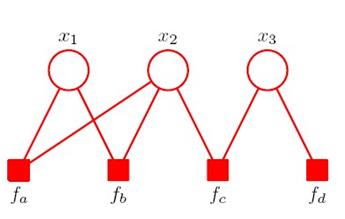
上面的x1,x2,x3是原图的随机变量 ,下面的fa,fb,fc,fd是factor节点,只有随即变量节点和factor节点之间有连接,每类节点自身互不连接,每个factor连接的变量节点,是相互依赖的节点。
kxkr<lxfkxkr@126.com> 20:42:10
就是一个clique中的节点吧
网神(66707180) 20:42:19
对,严格的说,也不是。
kxkr<lxfkxkr@126.com> 20:44:15
对于有向图 ?
网神(66707180) 20:45:10
x1,x2,x3是一个最大团. 可以只用一个factor节点,如中间那个图
kxkr<lxfkxkr@126.com> 20:45:17
嗯
网神(66707180) 20:45:22
也可以用多个factor节点,如右边图,但什么情况下用一个factor什么情况用多个factor,我没想明白
kxkr<lxfkxkr@126.com> 20:47:10
嗯,继续
网神(66707180) 20:47:21
转换成factor图后,就是树形图了,符合前面树形图的两种情况,这时候,要求一个节点或一组节点的边界概率,用一种叫做sum-product的方法,已求一个节点的边界概率为例.
η<liyitan2144@163.com> 20:49:50
 虽然也对具体的应用情景不清楚,但是一个factor能表达的信息比使用多个factor能表达的信息多.
虽然也对具体的应用情景不清楚,但是一个factor能表达的信息比使用多个factor能表达的信息多.
网神(66707180) 20:51:06
单个的factor表达的信息多,而且节点越少,计算越简单,所以是不是尽量用少的factor?max-product求单个节点的边界概率,其思想是以该节点为root。
η<liyitan2144@163.com> 20:52:38
但是,从设计模型的角度看,节点少了,一个节点设计的复杂程度就大了,不一定容易设计,拆解成多个factor,每个factor都很简单,设计方便。
kxkr<lxfkxkr@126.com> 20:54:37
文中貌似倾向于一个单个的factor
 η<liyitan2144@163.com> 20:56:57
η<liyitan2144@163.com> 20:56:57
这貌似是在表达一个通用的方法,和是把大的clique的factor拆解成小的多个factor没有关系。
kxkr<lxfkxkr@126.com> 20:57:53
拆成多个factor是不是会造成参数变多,不容易求呢,继续吧,这个有待实践。η<liyitan2144@163.com> 21:00:00
参数应该会变多吧,不过模型其实简单了,确实有待实践,我觉得这和具体应用有关,比如在一副图像里面,如果仅仅表达”像素”的相似度,我们完全可以使用小factor。
网神(66707180) 21:00:39
我继续,prml这章图模型只讲了基础的概念,没讲常用的图模型实例,HMM和CRF这两大主流图模型方法还没讲,感觉不够直观.
我继续说inference. 转换成factor图后,求节点xi的边缘概率。把xi作为root节点,把求root边界概率理解成一个信息(message)传递的过程,从叶子节点传递概率信息到root节点.传递的规则是:
从叶子节点开始,如果叶子是变量节点,发送1给父节点,如果叶子是factor节点,发送f(x)给父节点.
对于非叶子节点,如果是变量节点,将其收到的message相乘,发给父节点,如果是factor节点,将其收到的message和自身f(x)相乘,然后做一个sum,发给父节点。
举个例子:
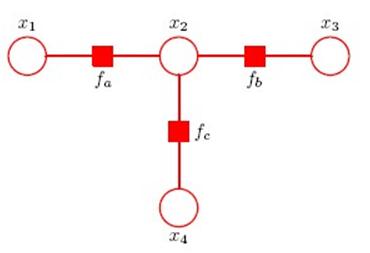
这个图中求x3的边缘概率,message传递的过程是:
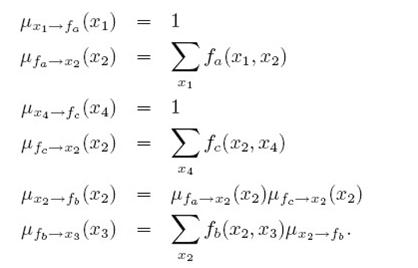
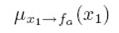 中的
中的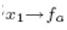 表示从节点x1传递到fa,最后p(x3)是等于
表示从节点x1传递到fa,最后p(x3)是等于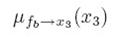 ,因为只有一个fb节点向其传入信息,如果要求x2的边界概率,因为x2有三个节点出入信息,分别是:
,因为只有一个fb节点向其传入信息,如果要求x2的边界概率,因为x2有三个节点出入信息,分别是:
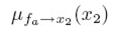
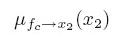
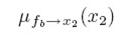
所以p(x2)就等于这三个信息的乘积
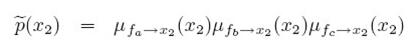
这个结果与边界分布的定义是相符的,x2的边界定义如下:
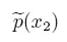
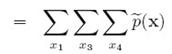
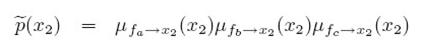 通过这个,可以推导出上面的边界分布. 推导如下:
通过这个,可以推导出上面的边界分布. 推导如下:
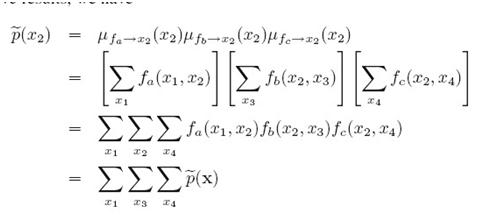
上面就是用sum-product来求边缘分布的方法。
不知道讲的是否明白,不明白就看书吧,一起研究 今天就讲到这了,大家有啥问题讨论下。
今天就讲到这了,大家有啥问题讨论下。
huajh7(284696304) 21:34:52
补充几点,一是 temporal model ,如Dynamical Bayesian newtwork(DBN), plate models ,这是图模型的表达能力; 二是belief Bropagation ,包括exact 和approximation ,loopy时的收敛性; Inference包括MCMC,变分法。这是图模型在tree和graph的推理能力。三是Structure Learning ,BIC score等。这是图模型的学习能力。
注:PRML读书会系列文章由 @Nietzsche_复杂网络机器学习 同学授权发布,转载请注明原作者和相关的主讲人,谢谢。
PRML读书会讲稿PDF版本以及更多资源下载地址:http://vdisk.weibo.com/u/1841149974