PRML读书会第五章 Neural Networks
主讲人 网神
(新浪微博:@豆角茄子麻酱凉面)
网神(66707180) 18:55:06
那我们开始了啊,前面第3,4章讲了回归和分类问题,他们应用的主要限制是维度灾难问题。今天的第5章神经网络的内容:
1. 神经网络的定义
2. 训练方法:error函数,梯度下降,后向传导
3. 正则化:几种主要方法,重点讲卷积网络
书上提到的这些内容今天先不讲了,以后有时间再讲:BP在Jacobian和Hessian矩阵中求导的应用;
混合密度网络;贝叶斯解释神经网络。
首先是神经网络的定义,先看一个最简单的神经网络,只有一个神经元:
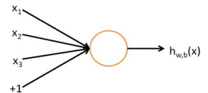
这个神经元是一个以x1,x2,x3和截距1为输入的运算单元,其输出是:

其中函数f成为”激活函数” , activation function.激活函数根据实际应用确定,经常选择sigmoid函数.如果是sigmoid函数,这个神经元的输入-输出的映射就是一个logistic回归问题。
神经网络就是将许多个神经元连接在一起组成的网络,如图:
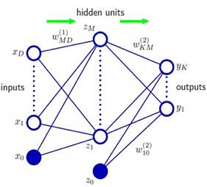
神经网络的图跟后面第八章图模型不同, 图模型中,每个节点都是一个随机变量,符合某个分布。神经网络中的节点是确定的值,由与其相连的节点唯一确定。
上图这个神经网络包含三层,左边是输入层,x1…xd节点是输入节点, x0是截距项。最右边是输出层,y1,…,yk是输出节点. 中间是隐藏层hidden level, z1,…,zM是隐藏节点,因为不能从训练样本中观察到他们的值,所以叫隐藏层。
可以把神经网络描述为一系列的函数转换。首先,构造M个输入节点的线性组合:
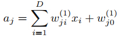
上式中,j=1,…,M,对应M个隐藏节点. 上标(1)表示这是第一层的参数。wji是权重weight,wj0是偏置. aj 叫做activation. 中文叫激活吧,感觉有点别扭。
把activation aj输入到一个非线性激活函数h(.) 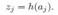 就得到了隐藏节点的值zj。
就得到了隐藏节点的值zj。
在这个从输入层到隐藏层的转换中,这个激活函数不能是线性的,接下来,将隐藏节点的值线性组合得到输出节点的activation:
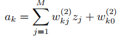
每个ak输入一个输出层激活函数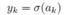 ,就得到了输出值。
,就得到了输出值。
这个从隐藏层到输出层的激活函数σ,根据不同应用,有不同的选择,例如回归问题的激活函数是identity函数,既y = a.分类问题的激活函数选择sigmoid函数,multiclass分类选择是softmax函数.
把上面各阶段的计算连起来,神经网络整个的计算过程就是:
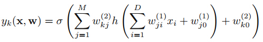
上面计算过程是以2层神经网络为例。实际使用的NN可能有多层,记得听一个报告现在很火的deep learning的隐藏层有5-9层.这个计算过程forward propagation,从前向后计算。与此相反,训练时,会用back propagation从后向前来计算偏导数。
神经网络有很强的拟合能力,可以拟合很多种的曲线,这个图是书上的一个例子,对四种曲线的拟合:
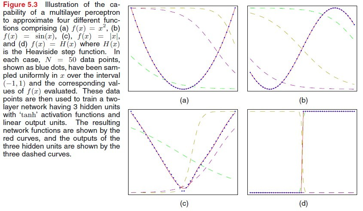
第一部分神经网络的定义就这么多,大家有没有什么问题啊?
============================讨论=================================
阳阳(236995728) 19:20:43
输入层到隐藏层使用的激活函数与隐藏层到输出层的激活函数是否要一致?
网神(66707180) 19:21:11
两层激活函数不一定一致,输入层到隐藏层 经常是sigmoid函数。 而隐藏层到输出层,根据应用不同,选择不同.
牧云(1106207961) 19:22:30
一般的算法,比如神经网络,都有分类和拟合的功能,分类和拟合有共同点吗?为什么能拟合,这个问题我没有找到地方清晰的解释。
独孤圣者(303957511) 19:23:47
拟合和分类,在我看来实际上是一样的,分类无非是只有2个或多个值的拟合而已。2个值的拟合,被称为二值分类
ant/wxony(824976094) 19:24:30
不是吧,svm做二值分类,就不是以拟合为目标。二值拟合可以用做分类。
独孤圣者(303957511) 19:29:42
可以作为概率来理解吧,我个人认为啊,sigmoid函数,是将分类结果做一个概率的计算。
阳阳(236995728) 19:24:07
输入层到隐藏层 经常是sigmoid函数 那么也就是特征值变成了【0-1】之间的数了?
网神(66707180) 19:25:19
是的,我认为是.机器学习经常需要做特征归一化,也是把特征归一化到[0,1]范围。当然这里不只是归一化。
阳阳(236995728) 19:26:56
这里应该不是归一化的作用@网神
网神(66707180) 19:27:33
嗯,不是归一化,我觉得神经网络的这些做法,没有一个科学的解释。不像SVM每一步都有严谨的理论。
罗杰兔(38900407) 19:29:00
参数W,b是算出来的,还是有些技巧得到的。因为常听人说,神经网络难就难在调试参数上。
阳阳(236995728) 19:29:11
我觉得神经网络也是在学习新的特征 而这些特征比较抽象难于理解@牧云 @网神
网神(66707180) 19:29:48
对,我理解隐藏层的目的就是学习特征
阳阳(236995728) 19:30:24
是的 但是这些特征难于理解较抽象@网神
网神(66707180) 19:30:47
最后一个隐藏层到输出层之间,就是做分类或回归。前面的不同隐藏层,则是提取特征。
独孤圣者(303957511) 19:30:52
隐藏层的目的就是学习特征,这个表示赞同
网神(66707180) 19:31:33
后面讲到卷积网络时,可以很明显感受到,隐藏层的目的就是学习特征。
阳阳(236995728) 19:31:59
但是我不理解为什么隐藏层学习到的特征值介于【0-1】之间是合理的?是归一化的作用?
牧云(1106207961) 19:32:47
归一化映射
Wilbur_中博(1954123) 19:33:59
要归一化也是对每一个输入变量做吧。。各个输入变量都组合在一起了,归一化干嘛。我理解就是一个非线性变换,让神经网络具有非线性能力。sigmoid之外,其他非线性变换用的也蛮多的。和归一化没什么关系。不一定要在[0, 1]之间。
独孤圣者(303957511) 19:39:50
这个解释我很同意,tanh函数也经常替换sigmoid函数,在神经网络中普遍使用。
网神(66707180) 19:39:59
嗯,让NN具有非线性能力是主要原因之一。
牧云(1106207961) 19:40:03
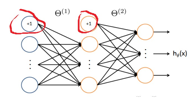
这个1要的干嘛
网神(66707180) 19:40:18
这个是偏置项,y = wx+b, 那个+1就是为了把b 合入w,变成 y=wx
罗杰兔(38900407) 19:41:36
Ng好象讲b是截距
网神(66707180) 19:43:16
截距和偏执项是一个意思。 放在坐标系上,b就是截距
阳阳(236995728) 19:40:33
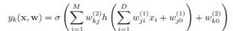 它可以逼近任意的非线性函数吗@网神
它可以逼近任意的非线性函数吗@网神
网神(66707180) 19:42:13
书上没说可以逼近任意曲线,说的是逼近很多曲线
阳阳(236995728) 19:42:58
它到底是怎么逼近的啊@网神 我想看看多个函数叠加的?
网神(66707180) 19:44:30
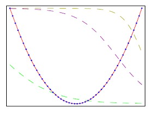
就是多个函数叠加。这个图上那个抛物线就是最终的曲线,由另外三条曲线叠加而成,另外那三条,每条是一个隐藏节点生成的曲线。
阳阳(236995728) 19:45:05
这三条曲线用的函数形式是不是一样的
zeno(117127143) 19:45:31
理解nn怎么逼近xor函数,就知道怎么非线性的了
HX(458728037) 19:45:56
问一句,你现在讲的是BP网络吧?
网神(66707180) 19:46:07
是BP网络
========================讨论结束===============================
网神(66707180) 19:46:59
接下来是神经网络的训练。神经网络训练的套路与第三,四章相同:确定目标变量的分布函数和似然函数,
取负对数,得到error函数,用梯度下降法求使error函数最小的参数w和b。
NN的应用有:回归、binary分类、K个独立binary分类、multiclass分类。不同的应用决定了不同的激活函数、不同的目标变量的条件分布,不同的error函数.
首先,对于回归问题,输出变量t的条件概率符合高斯分布:
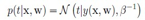
因此,给定一个训练样本集合,其似然函数是:
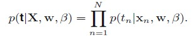
error函数是对似然函数取 负对数,得到:
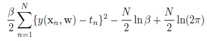
最小化这个error函数,只需要最小化第一项,所以回归问题的errro函数定义是:
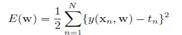
回归问题的隐藏层到输出层的激活函数是identity函数,也就是 
ak就是对隐藏层节点的线性组合:
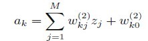
这样有了error函数,就可以同梯度下降法求极值点.
再说说binary分类和multiclass分类的error函数:
binary分类的目标变量条件分布式伯努利分布:
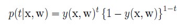
这样,通过对似然函数取负对数,得到error函数如下:
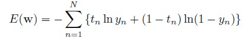
另外binary分类,隐藏层到输出层的激活函数是sigmoid函数。对multiclass问题,也就是结果是K个互斥的类别中的一个.类似思路可以得到其error函数.这里就不说了。书上都有.
知道了error函数,和激活函数,这里先做一个计算,为后面的BP做准备,将E(w)对激活ak求导,可得:
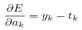
这里有意思的是,不管是回归、binary分类还是multiclass分类,尽管其error函数不同,这个求导得出的结果都是yk-tk
回归问题这个求导很明显,下式中,y = a, 所以对a求导就是 y – t.
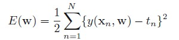
其他错误函数,需要推导一下,这里就不推了。有了error函数,用梯度下降法求其极小值点。
因为输入层到隐藏层的激活函数是非线性函数,所以error函数是非凸函数,所以可能存在很多个局部极值点。
两栖动物(9219642) 20:07:40
你这里说的回归问题是用神经网络拟合随机变量?
网神(66707180) 20:07:56
是的,就是做线性回归要做的事.只是用神经网络的方法,可以拟合更复杂的曲线。这是我的理解。
梯度下降法的思路就是对error函数求导,然后按下式对参数作调整:
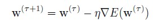
一直到导数为0,就找到了极值点.
这是基本思路,实际上很多算法,如共轭梯度法,拟牛顿法等,可以更有效的寻找极值点。因为梯度下降是机器学习中求极值点的常用方法,这些算法不是本章的内容,就不讲了,有专门的章节讲这些算法。
这里要讲的是error函数对参数w的求导方法,也就是back propagation后向传导法。
可以高效的计算这个导数。
这个导数的计算利用的 求导数的链式法则, 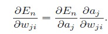
把E对w的求导,转换成E对activation a的求导 和 a 对w 的求导. 这个地方因为涉及的式子比较多,我在纸上写了一下,我整个贴上吧:

大家看看,可以讨论一下
阳阳(236995728) 20:21:30
error function是负对数似然函数吧
网神(66707180) 20:21:38
是的
天上的月亮(785011830) 20:22:35
更新hidden层的w,为什么利用偏导的chain rule呢?
网神(66707180) 20:22:49
最主要的结论就是:
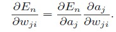
对于输出层的节点,
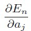
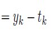
对于隐藏层的节点,
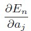
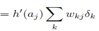
E对隐藏层节点w的导数,通过上式,就由输出层节点的导数 求得了.
有了上面求偏导数的方法,整个训练过程就是:
1.输入一个样本Xn,根据forward propagation得到每个hidden单元和output单元的激活值a.
2.计算每个output单元的偏导数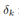
3.根据反向传导公式,计算每个hidden单元的
4.计算偏导数。
5.用一定的步长更新参数w。
循环往复,一直找到满意的w。
独孤圣者(303957511) 20:32:09
BP时,是不是每个样本都要反馈一次?
网神(66707180) 20:33:32
应该是每个样本都反馈一次,batch也是.batch形式的每个样本反馈一次,将每个样本的偏导数求和,如下式,得到所有样本的偏导数,然后做一次参数w的调整.
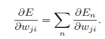
接下来就讲正则化,神经网络参数多,训练复杂,所以正则化方法也被研究的很多,书上讲了很多种的正则化方法. 第一个,就是在error函数上,加上正则项。
第三章回归的正则项如下:
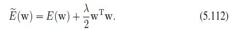
后面那一项对过大的w做惩罚。
但是对神经网络,正则项需要满足 一个缩放不变性,所以正则项的形式如下:
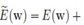
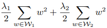
这个形式怎么推导出来的,大家看书吧,这里不说了。
书上讲到的第二种正则化方法是early stop,我理解的思路就是 在训练集上每调整一次w, 得到新的参数,就在验证集上验证一下。 开始在验证集上的error是逐渐下降的,后来就不下降了,会上升。那么在开始上升之前,就停止训练,那个参数就是最佳情况。
忘了说一个正则化注意对象了,就是隐藏节点的数量M。这个M是预先人为确定的,他的大小决定了整个模型的参数多少。所以是影响 欠拟合还是过拟合的 关键因素。
monica(909117539) 20:42:38
开始上升是出现了过拟合么?节点数量和层数都是怎样选择的呀?
网神(66707180) 20:42:56
开始上升就是过拟合了,是的,在训练集上,error还是下降的,但验证集上已经上升了。节点数量M是人为确定,我想这个数怎么定,是NN调参的重点。
monica(909117539) 20:44:36
:)
网神(66707180) 20:44:38
ML牛的人,叫做 调得一手好参,我觉得这里最能体现。
这个图是不同的M值对拟合情况的影响:
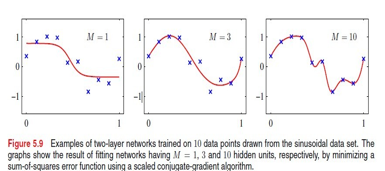
另外,因为NN又不是凸函数,导致train更麻烦
monica(909117539) 20:47:01
嗯,这个能理解,前面模型太简单,欠拟合了,后面模型太复杂,就过拟合了。
网神(66707180) 20:47:08
需要尝试不同的M值,对于每一个M值,又需要train多次,每次随即初始化w的值,然后尝试找到不同的局部极值点。
上面说了三种正则化方法。接下来,因为神经网络在图像识别中,应用广泛,所以图像识别对正则化有些特殊的需求,就是 平移、缩放、旋转不变性。不知道这个需求在其他应用中,是否存在,例如NLP中,反正书上都是以图像处理为例讲的.
这些不变形,就是图像中的物体位置移动、大小变化、或者一定程度的旋转, 对ouput层的结果应该没有影响。
这里主要讲卷积神经网络。这个东东好像很有用,我看在Ng的deep learning教程中也重点讲了,当图像是大图时,如100×100像素以上,卷积网络可以大大减少参数w的个数.
卷积网络的input层的unit是图像的像素值.卷积网络的hidden层由卷积层和子采样层组成,如图:
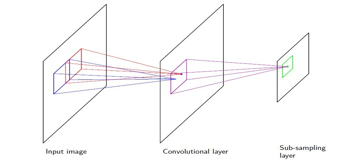
一个卷及网络可能包括多个卷积层和子采样层,如下图有两对卷积/子采样层:
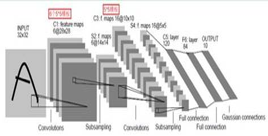
卷积层的units被划分成多个planes,每个plane是一个feature map,一个feature map里的一个unit只连接input层的一个小区域,一个feature map里的所有unit使用相同的weight值。
卷积层的作用可以认为是提取特征。每个plane就是一个特征滤波器,通过卷积的方式提取图像的一种特征,过滤掉不是本特征的信息。比如提取100种特征,就会有100个plane,上图中,提取6个特征,第二层有6个平面。
一个plane里面的一个unit与图像的一个子区域相连,unit的值表示从该区域提取的一个特征值。共有多少个子区域,plane里就有多少个unit。
以上图为例,输入图像是32×32像素,所以input层有32×32个unit. 取子区域的大小为4×4,,那么共有28×28个子区域。每个子区域提取得到6个特征,对应第二层有6个plane, 每个plane有28×28个unit.
这样一个plane里的一个unit与输入层的4×4个unit相连,有16个权重weight值,这个plane里的其他unit都公用16个weight值.
这样,6个平面,共有16×6=96个weight参数和6个bias参数.
下面说子采样层,上面说道,6个平面,每个平面有28×28个unit,所以第二层共有6x28x28个unit. 这是从图像中提取出来的特征,作为后一层的输入,用于分类或回归。
但实际中,6个特征远远不够,图像也不一定只有32×32像素。假如从96×96像素中提取400个特征,子区域还是4×4,则第二层的unit会有 400 x (96-4) x (96-4) = 300多万。 超过300多万输入的分类器很难训练,也容易过拟合。
这就通过子采样来减少特征。子采样就是把卷积层的一个平面划分成几部分,每个部分取最大值或平均值,作为子采样层的一个unit值.如下图:
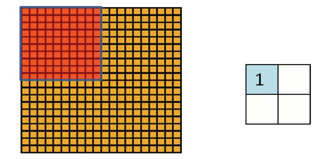
左边表示卷积层的一个plane,右边是这个plane的子采样结果。一个格子表示一个unit。
把左边整个plane分成4部分,互相不重合,每个部分取最大值或平均值,作为右边子采样层的一个unit。这样子采样层一个plane只有4个unit。
通过卷积和子采样:得到的特征作为下一层分类或回归的输入。
主要好处:
a. 这样输入层的各种变形在后面就会变得不敏感。如果有多对 卷积/子采样,每一对就将不变形更深入一层。
b. 减少参数的个数。就这么多了,大家慢慢看。
阳阳(236995728) 21:01:30
关于卷积神经网络的材料有吗?@网神
阿邦(1549614810) 21:01:44
问个问题,cnn怎么做的normalization?
网神(66707180) 21:03:26
卷积网络的材料,我看了书上的,还有Andrew Ng的deep learning里讲的,另外网上搜了一篇文章
这里我贴下链接。
罗杰兔(38900407) 21:04:19
不大明白为什么可以采样,怎么保证采样得到的信息正好是我们需要的
阿邦(1549614810) 21:05:01
采样是max pooling,用于不变性
网神(66707180) 21:05:02
http://ibillxia.github.io/blog/2013/04/06/Convolutional-Neural-Networks/
牧云(1106207961) 21:05:02
采样是随机的吗?
网神(66707180) 21:06:40
传了个deep learning教程。这是Andrew Ng上课的notes, 网上一些人众包翻译的,我觉得翻译的不错。里面讲了神经网络、卷积网络,和其他深度网络的东西。
采样不是随机的。
牧云(1106207961) 21:08:04
卷积提取的特征具有稳定性吗
阿邦(1549614810) 21:08:56
据说要数据量很大才可以
网神(66707180) 21:09:03
卷积层和子采样层主要是 解决 不变性问题 和减少参数w数量问题,所以可以起到泛化作用.
注:PRML读书会系列文章由 @Nietzsche_复杂网络机器学习 同学授权发布,转载请注明原作者和相关的主讲人,谢谢。